
Functional Requirements
- View and search a list of coding questions (based on difficulty level, topic/tag, question name, competition status);
- View a question, and be able to code a solution in multiple language;
- Submit a solution and get submission result;
- View a live leaderboard for competition;
Non-Functional Requirements
- The system should be highly available for common operations including viewing/searching questions, accepting/validating code submission and returning submission results.
- The system should be scalable to support 10K concurrent submissions (handle peak of 5*X);
- The system should be efficient to return submission results within ≤ 5 seconds;
- The system should support real-time update/view of a leaderboard;
- [Must-have] The system should support isolation and security when executing user-submitted code (to prevent tearing down the system by malicious code submission);
Below the line
- Recommend questions based on users browsing or submission history
- User registration (premium) and management
- Share or post questions into social media apps
API
High Level Design
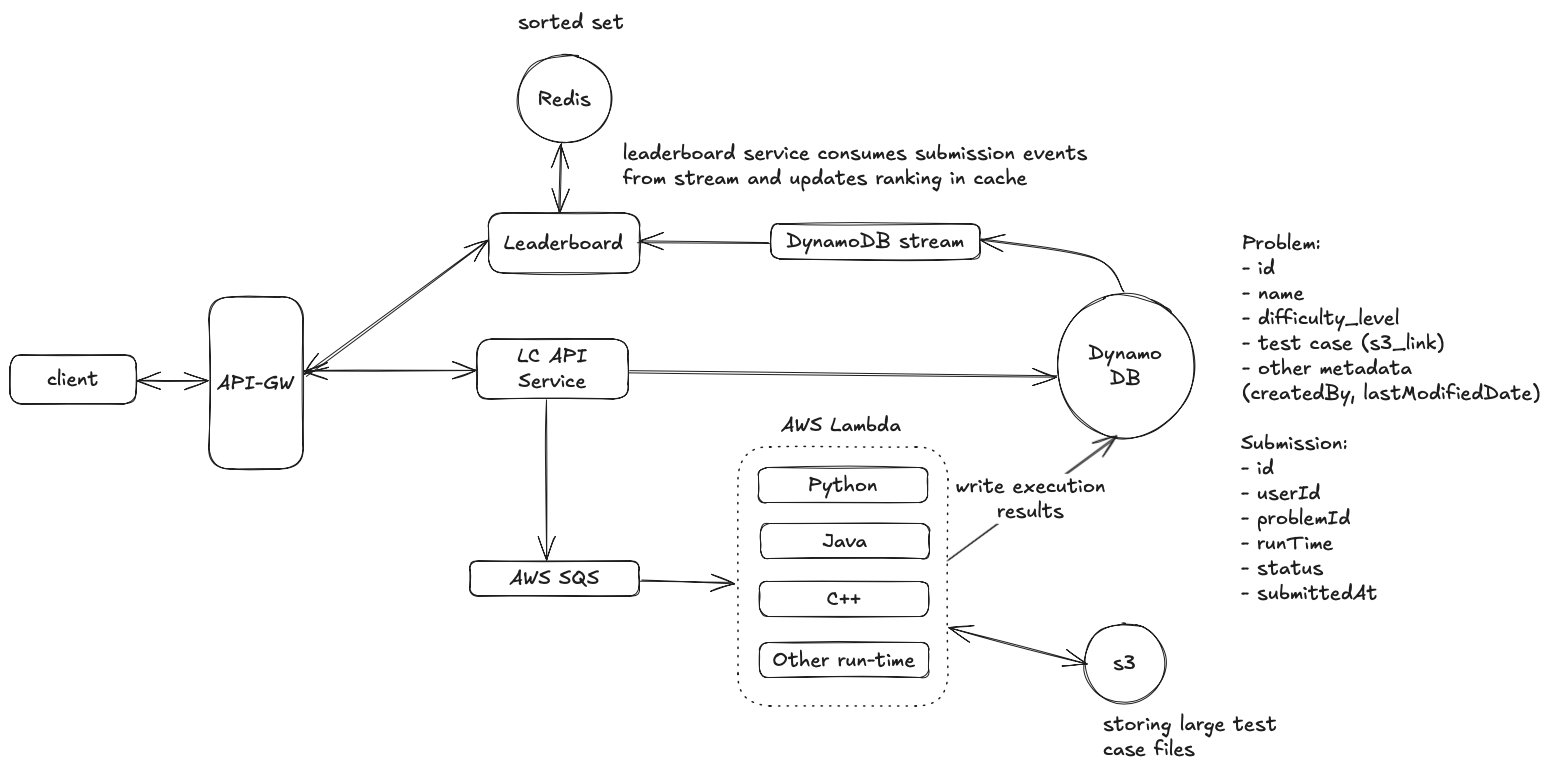
View and search a list of coding questions
- Clients send REST API requests to retrieve a list of coding questions based on search terms such as difficulty_level, tag, or completion_status.
- Upon receiving a request, the API Server first queries the cache (e.g., Redis) for the results and falls back to the database if the cache does not contain the requested data. The results are then returned to the client.
View a question, and be able to code a solution in multiple language
- Client sends a request to the API server (GET /problem/:id) to view a specific question.
- The API server returns question details including description and initial code dumps etc. On the browser, we could use CodeMirror or Monaco Editor for rendering an IDE-like tool so that users can code a solution.
Submit a solution and get submission result
Workflow
When a client submits code, the API server creates a submission record in the database and publishes a message to a language-specific SQS queue. The server returns a submission ID to the client immediately. The client periodically sends requests (/v1/submissions/{id}/check) to retrieve submission status. Upon receiving a check request, the API server queries the submission table and returns the current status to the client.
Design Options
(1) Worker Type (VM vs Docker vs Lambda)Choosing the right runtime environment is crucial for a LeetCode-like system. Based on non-functional requirements:AWS Lambda is preferred and a great option because it aligns well with the requirement of blast radius containment and low latency for setting up and tearing down environments.
- Failures should be isolated to ensure one worker’s issue doesn’t affect others ("blast radius" containment).
- The system must handle user submissions efficiently, returning results within 5 seconds, so the environment should be easy to spawn and dispose of with minimal setup/teardown latency.
(2) Single queue vs multiple queues (or single topic vs multiple topics if using Kafka)
- [Option 1] We recommend to use separate (language-specific) queues or creating separate topics (if Kafka is used). Each language run-time workers can scale independently. For example, we can have dedicated queues for popular languages (Java, Python etc). Then, we can monitor queue (message count, throughput, latency etc) and scale workers dynamically.
- [Option 2] An alternative is to use single queue with event filtering. API server publishes messages to the same queue. Workers polls the SQS queue for messages, evaluates each message against the filter criteria defined in the
Event Source Mapping(an Lambda configuration). If the message matches the filter criteria, Lambda invokes the function and execute. If the message does not match, Lambda skips it and continues polling.
(3) How does a worker report execution result/status?
When a worker completes code execution, it writes the results directly to the submission table in the database. The client periodically sends requests (e.g., every second) to retrieve submission status. Upon receiving a check request, the API server queries the submission table and returns the current status to the client.
View a live leaderboard for competition
To support a real-time competition leaderboard that ranks participants by total score and submission time, we need a data store that excels at both frequent updates and ordered data retrieval. We will re-use the existing submission table in DynamoDB and add a new leaderboard service responsible for calculating scores and maintaining rankings. Redis sorted sets will handle real-time ranking operations, providing efficient ordered data access.
Data Storage
- To re-use existing submission table for storing submission details for a competition (v.s practice), we can add a new column — competitionId.
- Redis SortedSet
competition:{id}:rankings (Sorted Set)
Score: total_score
Member: user_idRanking Update workflow
When a submission in a competition is processed, DynamoDB streams captures submission updates. Leaderboard Lambda processes stream events:
- Filters for competition submissions
- Calculates score from submission test results
- Gets user's current total score from Redis (ZSCORE command) and then updates Redis sorted set with new total_score.
Leaderboard Query workflow
- Serve rankings from Redis sorted set using ZREVRANGE
- Fall back to calculating rankings from DynamoDB if Redis is unavailable
Deep Dive
High Availability for Serving View, Search, and Submit Requests
- Multi-instance API Servers: Deploying multiple instances of the API server behind an AWS API Gateway or an Application Load Balancer (ALB) ensures redundancy. If one instance fails, traffic is automatically routed to healthy instances.
- AWS Lambda & DynamoDB: These managed services provide built-in fault tolerance across multiple availability zones. DynamoDB offers automatic replication and failover, ensuring data persistence and availability.
- Handle Redis failure. Fail back to DynamoDB and replay or re-build leaderboard using AOF log files. When Redis cluster is down due to node failures or network failures, leaderboard service can fail back to pull scores from dynamoDB, and re-build leaderboard using AOF logs.
Support 10K concurrent submissions (peak: 5X)
Handling up to 10K concurrent submissions requires efficient workload distribution and rapid function executions. This can be satisfied by followings:
- Language-specific queues. Using AWS SQS with separate queues for different programming languages allows independent scaling of workers. Popular languages like Python and Java can have dedicated, dynamically scalable queues.
- Scaling AWS Lambda.
- Increase concurrent limit By default, AWS Lambda can handle up to 1K concurrent invocations (per AWS account per region). For higher concurrent invocation, we could request limit increase to accommodate the expected peak load.
- Monitor and adjust dynamically. When lambda processes messages from a queue, which acts as a buffer to handle sudden spikes in submissions without overwhelming the system. When Lambda is throttled (due to concurrency limits), SQS retain the messages and Lambda processes them as resources become available. We can monitor based on SQS and Lambda metrics (such as: #visible message, age of the oldest message, #concurrent execution) and dynamically adjust.
Return submission results within ≤ 5 seconds
Use Provisioned Concurrency to optimize code execution environments. We use Lambda as compute to execute user-submitted code. We can set provisioned currency beforehand to “pre-warm” lambda instances, to minimize cold start delay for predictable workloads (when hosting a competition).
[Security Control] Support isolation and security when executing user-submitted code
- Sandboxed executions and limit the max resource consumption. Each submission runs in an isolated AWS Lambda environment, containing potential failures or security breaches within a single invocation. Strict CPU, memory, and execution time limits prevent resource exhaustion attacks.
- Enforce timeout on code execution. Enforce timeout or max run-time and terminate the execution to prevent infinite loops or excessive recursion.
[Performance] Support real-time update/view of a leaderboard
Maintaining a live leaderboard requires an efficient ranking system that supports frequent updates and real-time queries. The approach includes:
- Redis Sorted Sets for Fast Ranking Updates:
- Each competition has a dedicated sorted set. competition:{id}:rankings.
- The total score is the primary ranking criterion, while the submission timestamp is used to break ties.
- Updates occur via the ZADD command, ensuring an efficient O(log N) time complexity.
- Real-time updates through DynamoDB stream:
- Submission records are stored in DynamoDB with an indexed competitionId field.
- Leaderboard Lambda functions process DynamoDB Streams, updating Redis rankings in real-time.