
Functional Requirements
- Search for business entities by location (and name, category, open_now…)
- View business details
- Review a business entity with a rating (1 ~ 5) and optional text review (or attaching photos);
Non-Functional Requirements
- (Availability >> Consistency) The system should be highly available in accepting/serving all client requests (such as: view, search and review). The system can be eventually consistent in displaying all comments for a business.
- (Scalability) The system should be able to handle up to 10 M businesses and 100 M monthly active users.
- (Performance. Read >> Write) The system should prioritize read performance. Read/Search should be fast (< 1 ~ 2 seconds).
- (Fault Tolerant) The system should be able to tolerant individual component failures.
- (Compliance) A user can rate business ONLY ONCE.
Below the line
- Admin / Business owners should be able to add, update or remove business
- System recommends business to users based on browsing history
- (IAM) Anything user registration/management.
API Design
- Search for business.
- View business details
- Review a business
High Level Design
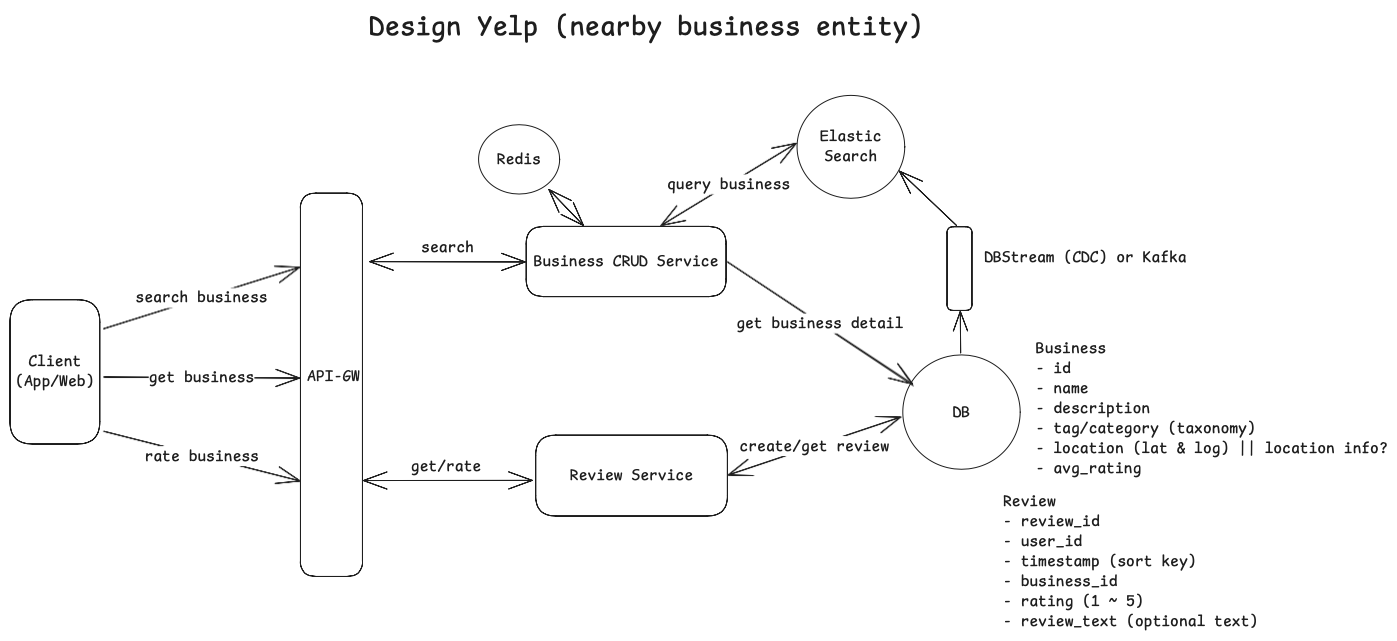
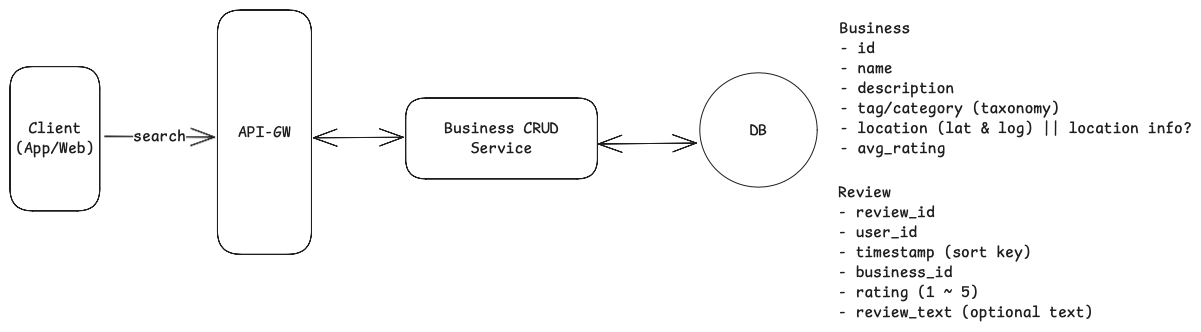
Search for business entities by location
Let’s start with something simple (Simple DB-backed CRUD service pattern)
This should “just” work. And the workflow is
- Client sends a GET request to search for a business with some search parameters (within 1 mile of a location, open now, sort by average_rating).
- API-GW routes the request to Business CRUD service. Business CRUD queries the Database and return results to client.
Database Options
- Requirements
- In Yelp case, Read >> Writes. Admin/Owner may not add/update business entities frequently. But Yelp users can frequently search/view business details. Read/search needs to be very fast.
- Back-of-the-envelope estimation
- Yelp (as of 05/2024) has 60.28M monthly active users (round it to 100 M).
- DAU = 100 M * 20% ~ 30% = 20 M ~ 30 M (for moderate engagement app).
- Assume each user searches 2 ~ 5 times in a day, then QPS =
- lower bound: 20M * 2 / (10^5 seconds in a day) = 400 QPS;
- high bound: 30M * 5 / 10^5 seconds in a day) = 1,500 QPS;
- Peak (3 times * average) = (400 + 1500) / 2 * 3 = 2850 ~ 3,000 QPS;
- Options
- Option 1: Postgres + PostGIS. PostGIS extension provides native support for storing geospatial data using data types like
POINT(lon + lat) andPOLYGONfor complex areas. - Option 2: Cassandra + Elastic Search. Cassandra does not provide native support for geospatial data. We could store geo locations (coordinates) as decimal (Double type) in cassandra and uses elastic search to support geo-distance queries.
- Option 1: Postgres + PostGIS. PostGIS extension provides native support for storing geospatial data using data types like
View business details
User gets list of business entities from search result (id, name, distance, rating etc). Then user can click on individual business (which sends a GET request to backend serviceGET /v1/business/:businessId -> BusinessDetail. Business CRUD service fetches business metadata from DB using businessId (primary_key) and returns business details to users (i.e: business exact location, contact, open hours, rating, menus, recent 10 helpful/critical reviews etc etc);
Review a business entity with a rating (1 ~ 5) and optional text review
The workflow of user posting a review for business entity is given as below:
- User sends a POST request to the backend (business CRUD service)
POST /v1/business/:businessId/ --> status (200: Success; 4xx/5xx: Failure)
body: {
- JWT token
- businessId;
- rating;
- (optional) text;
- S3 link;
}
- Business CRUD service processes the review request (i.e: validating the content is appropriate) and then inserts into DB (review table) and update average rating for the business.
Interesting talk points
- 1. Should creating reviews be handled by a separate service?
- Yes. We should. Why? Let’s say, we have 100 people using the app, but maybe only 10% (or even less) people would leave a review for a business. In other words, the number of requests for “post a review” would be significantly lower than “search/view a business”. They have different usage pattern (hence different scaling requirements). We need to scale “view/search” and process those requests fast. So we need to separate review and search/view into two services and then horizontally (and independently) scale view/search services.
- No. We should avoid. Why? Even they have different usage pattern, we could still handle all request by one services. The workflow of posting a review is simple enough to be grouped together with business view/search service. And we should avoid spinning up new services because it increases maintenance efforts or operational loads for the team (i.e: additional cost on infrastructure, monitoring…).
- 2. What if we want to support/allow users attaching photos in their review?
- When user clicks on “+” (or attach photo), front-end requests a presigned URL from review service.
- Review service generate S3 keys (paths) and returns an presigned URL.
- User uploads photos to S3 using presigned URL.
- Front end submits review request.
- Review service (in the backend) only handles S3 keys generation and persists review metadata into DB. Upload will be handled directly from client side to S3.
- 3. Only authorized user can post review.
- When user sends a new POST request to create a new review, we can validate the JWT token from request_body to ensure it’s a registered user.
- 4. User can comment a business ONLY once. (why? a malicious user could just send hundred of bad rating/review for a business…)
- This is again a very arguable topic. We want to enforce this because we don’t want malicious users to abuse the system (sending lots of repeated/spam or malicious comments). But does this mean, a user could only comment a business once during the whole life-time? That also sounds unreasonable. So we can lift this requirement to something like — “A user can only post a comment for a business once a day/week/month (to prevent spam). But a user can send an amendment or update their previous comment.” We can enforce this using database constraint (checking the timestamp).
Deep Dive
Prioritize Read and make Search fast.
- Indexing
- Postgres + PostGIS: Use geospatial indexes (GIST or SP-GiST) to optimize point and range queries
- Cassandra + ElasticSearch: Use Elasticsearch’s geo_point field type for indexing geo-coordinates. This enables fast geo_distance queries.
- Caching Use an in-memory cache like Redis to store results of commonly searched queries. (Top 10 highly-rated restaurants in popular cities);
- Distribute read workloads
- Postgres (Read Replicas):
- Configure read-only replicas to handle heavy read requests by routing read queries to nearest/different replicas. Use master for writes-only.
- Partition data by region (geography for GIS).
- Elasticsearch (horizontally scale): Use sharding to distribute query loads across multiple nodes. For example, businesses across various locations are stored in shards, possibly grouped by city or region. A search for restaurants within 5 miles of San Francisco Downtown will route to shards storing relevant data, reducing unnecessary processing by unrelated shards.
- Postgres (Read Replicas):
Highly available and can tolerant component failures.
- Handle component/service failures
- (Retry) For any request (i.e: view a business, search a business), we should implement retry (with exponential backoff) to mitigate transient failures. For client-end issues (anything 400, invalid user, inappropriate content etc), API server should fail the request with user-friendly error message.
- (Failover) We should setup monitoring on backend API servers. If degraded performance or server failure is detected, we can initiate fail-over to route all requests to a healthy server.
- Handle database failures
- (Failover to Replica) Enable automatic failover to replica if primary DB is down.
- (PIT) Enable data backup with point-in-time recovery to recover from latest checkpoint when data is corrupted or updated/deleted by mistakes;