
Functional Requirements
- Users should be able to create a new post with text content and optional media attachments.
- Users should be able to reply to a post (such as like or adding text comment).
- Users should be able to search posts by keywords and sort search results in chronological order or by view count;
- Users should be able to follow/unfollow other users.
Non-Functional Requirements
- The system should be fast in serving search requests (p90 < 500 ms).
- The system should be highly available (99.99% uptime) in serving requests such as creating a post, like a post, following a new user.
- The system should be scalable to support X users/posts (TBD)
- The system can adopt eventual consistency in displaying like count, comments.
- (Compliance) The system should check/filter harmful contents, hate speech etc.
Below the line
- The system can generate personalized search results based on users behaviors (browse/search history).
- Users can set visibility on posts (i.e: only visible to self, visible to a user group).
- User registration, single sign-on/off, MFA (basically anything IAM).
APIs
create a post
like a post
reply to a post
High-level Design
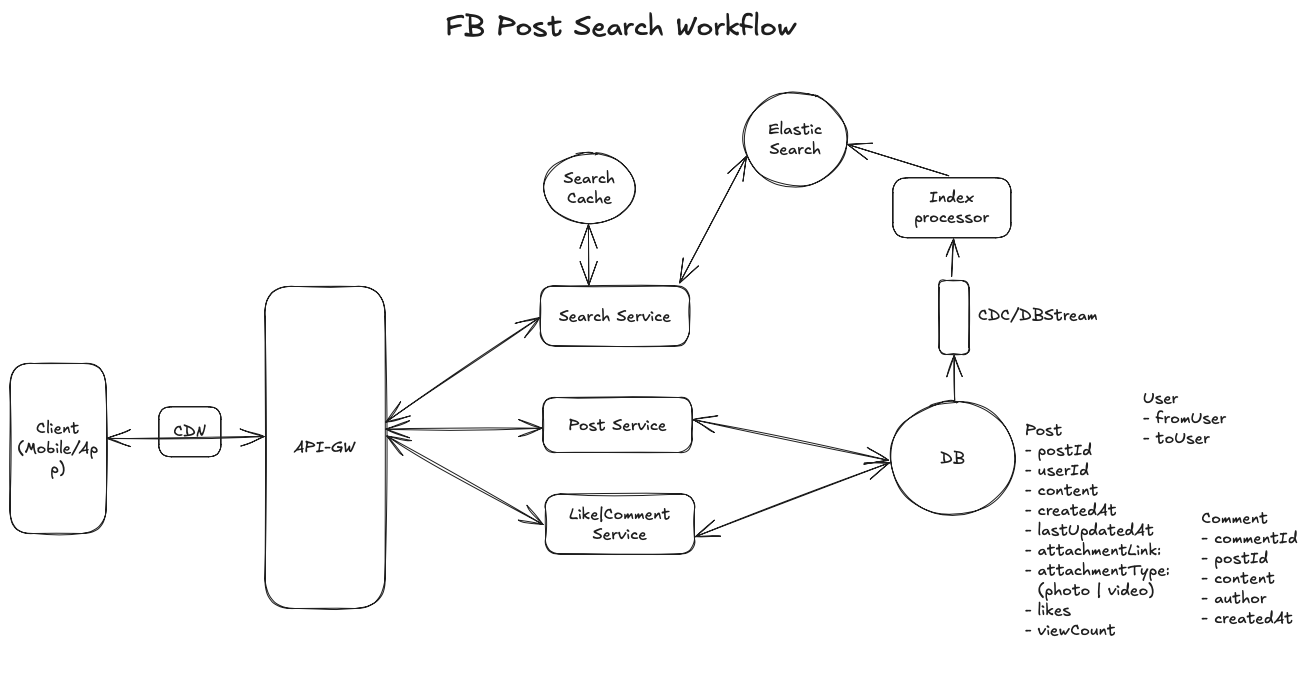
Create and reply to a post
Workflow
When a user sends a request of creating a post, liking a post, or replying to a post, the request is sent to the API gateway. The gateway performs initial validations, including rate limiting and JWT token verification, before routing the request to the appropriate backend service.
- For post creation, if the request includes media attachments, the client first obtains a pre-signed URL from the backend, which allows the media to be uploaded directly to AWS ****S3 without passing through the backend servers. After a successful upload, the client submits the post metadata (text content, media URLs, and additional metadata) to the Post Service, which performs the following operations:
- Runs content moderation checks on text content to filter out spam, hate speech, or harmful material.
- Stores post metadata (text content, media URLs, user details) in PostDB.
- Publishes an event to the Indexing Service for search indexing.
- Updates the Redis cache with the latest post data to optimize retrieval latency.
- For like and reply operations, the request is forwarded to the Comment Service, which updates the corresponding post engagement data:
- If the request is a reply, the text is stored in CommentDB.
- If the request is a like, an atomic update increments the like count in PostDB.
Database Option
Post Search
To allow users to search posts based on keywords, we need an efficient indexing and query system. While DynamoDB serves as our primary database, we need specialized search capabilities. Here are two design options for the search functionality:
Option 1: Build Custom Index ServiceThe custom index service subscribes to DynamoDB streams to process new posts in real-time. When a new post arrives, the service extracts searchable content and builds an inverted index mapping keywords to post IDs. To achieve fast query performance, the inverted index resides in Redis with AOF enabled for durability. For memory efficiency, only post IDs are stored in the index.When a search request arrives, the service follows these steps: First, it looks up relevant post IDs from the inverted index in Redis. Then, it queries DynamoDB to fetch the full content of matching posts. Finally, it returns the assembled results to the user. This approach provides basic search functionality suitable for smaller-scale deployments.
Option 2: Elasticsearch IntegrationFor more advanced search capabilities, we can leverage Elasticsearch (or AWS OpenSearch). This option provides built-in support for text analysis, relevance scoring, and distributed search.
High-level workflow diagram
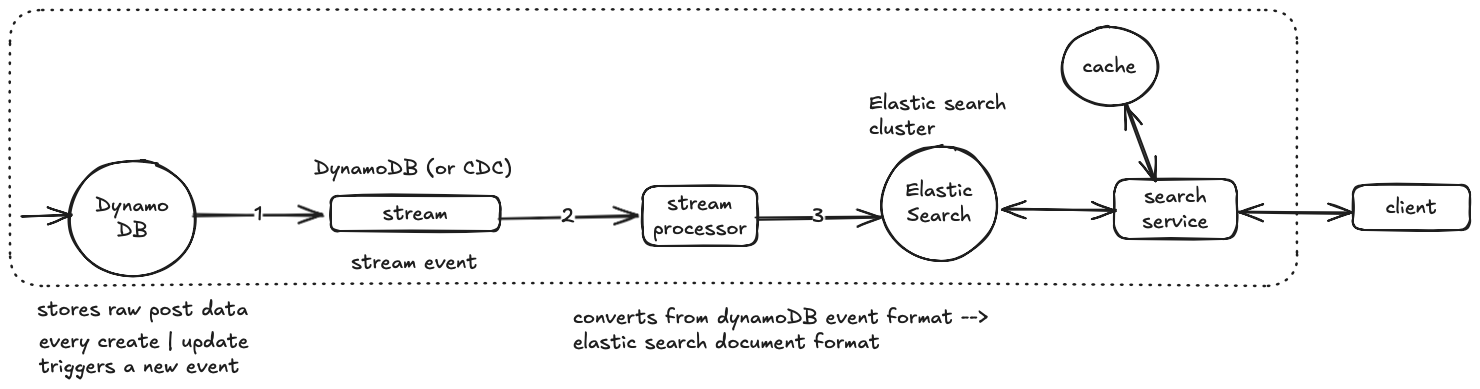
The indexing pipeline works as follows
- DynamoDB streams (or alternatively, Cassandra CDC with Kafka/Kinesis) emit change events for new or updated posts.
- Stream processor pre-process raw stream events. It filters unwanted data (i.e: no content change) and transforms data from dynamoDB stream event format (JSON format) into elastic search document format, lastly sends new documents to elastic search through elastic search clients/API. (stream processor options: AWS Lambda, Kinesis Firehose, any custom service.)
- Elastic search creates (or updates) its inverted index, mapping keywords to the document identifier (
postId) where those keywords appear.
For search queries, the workflow proceeds as follows:
- When a user submits a search request, the search service first checks the cache.
- On cache miss, it queries Elasticsearch. The service then caches results with a TTL aligned with our consistency requirements. This caching strategy helps meet our 500ms p90 latency target while maintaining reasonable freshness.
Trade-Offs to Consider (between option 1 and option 2)
- Development Effort: The custom Redis-based solution requires significant development work for features like text analysis and scoring. Elasticsearch provides these capabilities out of the box.
- Operational Complexity: Running Elasticsearch introduces additional operational overhead for cluster management and monitoring. The Redis solution is simpler but has scaling limitations.
- Query Capabilities: Elasticsearch supports advanced features like fuzzy matching, phrase queries, and complex aggregations. The custom solution would be limited to basic keyword matching initially.
Summary
- If we’re aiming to build a simple search service (no fuzzy, ranking, multi-word search), option 1 is sufficient and a good option to start with. Because it’s relatively easy to implement and has lower infrastructure costs and maintenance efforts.
- If we’re building a service that aims to be used by billions of users with complicated search user cases (fuzzy, ranking, multi-word search, custom filtering/sorting), option 2 is preferred.
Pagination
Efficient pagination is crucial for browsing large sets of search results while maintaining performance and user experience. The primary pagination strategy uses cursor-based navigation rather than offset-based pagination. When users submit a search query, the initial response includes both the first page of results and a pagination cursor. This cursor contains encoded information about the last item's sort key (timestamp or view count) and its unique identifier.
Pagination Challenges
- Time-based Sorting: When results are sorted by timestamp, the pagination flow works as follows: The search service queries Elasticsearch using a range query that selects posts before the cursor's timestamp. To handle posts with identical timestamps, we include the post_id in the sort criteria as a tiebreaker. This ensures stable ordering across page loads.
- Popularity-based Sorting: For view count sorting, additional complexity arises due to the dynamic nature of view counts. The pagination implementation must handle cases where a post's popularity changes during pagination. We address this by including both view_count and post_id in the cursor, maintaining result consistency within a single search session.
Deep Dive: Performance Optimizations
- Cache Management:
- Search results are cached with pagination metadata. The cache key includes both the search terms and cursor information. This allows efficient retrieval of subsequent pages while respecting our 500ms p90 latency requirement.
- As new posts are indexed or existing posts are updated, cached pagination results may become stale. The cache TTL is set to 30 seconds, aligning with our consistency requirements. This provides a balance between freshness and performance.
- Result Window Limits: To prevent excessive resource usage, we implement the following constraints: maximum page size: 50 items, maximum pagination depth: 1000 items.
Deep Dive
The system should be fast in serving search requests (p90 < 500 ms).
- Using Cache : The search service caches commonly searched results in memory with 1-minute TTL. Search service first checks cache before querying Elasticsearch.
- CDN Deployment: Frequently searched results are also stored in geographically distributed CDNs, reducing latency for users across different regions. CDN edge locations are selected based on user distribution.
The system should be scalable to support X users/posts.
- Assume we have 1 B daily active users. Each user sends 1 post on average and sends 10 comments and/or likes 10 posts per day.
- QPSs:
- post creation: 1 B * 1 post / day / 10^5 seconds/ day = 10^4 (10K) posts / second;
- comment & like event: 1 B * 10 likes / day / 10^5 seconds/ day = 100K likes or comments / second.
- How to handle?
- Scale up our DB.
- We briefly mentioned enabling auto-scaling on dynamoDB in high-level design. Here we’ll do detailed calculated on how much capacity are needed and how to set auto-scale policies. DynamoDB uses write capacity units for billing [link].
- Assume the average content size for each post is 1 KB, then each write would need 1 WCU (write capacity unit). For 10K writes per seconds, that is 10K WCU. Then we can have following configurations:
- set provisioned mode
- initial write capacity set to 10K WCU.
- scaling policy:
- min write capacity: 10 K
- max write capacity: 30 K (peak)
- target utilization percentage: 80%
- (With above dynamoDB auto scaling setting) a table can automatically increase its provisioned write capacity to handle sudden increases in traffics (when utilization is over 80% of 10 K) and can scale up to 30K.
- Scale up service instances.
- We can horizontally scale [post service] and [comment | like service] by adding more service instances (nodes).
- We can place an queue in front of services and create shards (using a high-cardinality shard key —
post_id + random_suffix (0 ~ 10) and have each service node to process 1 or couple shards.
The system should be highly available.
- Deploy services in multiple regions and/or availability zones. And monitor host status (resource utilizations) and service health (i.e: throughput, error rate, latency etc) and incorporates automatic failover mechanisms that respond to infrastructure issues without manual intervention.
- For request processing, the API Gateway serves as the first line of defense, implementing rate limiting and request validation. We utilize load balancers to distribute traffic across healthy instances, while circuit breakers prevent cascading failures by isolating problematic components.
The system should check/filter harmful contents, hate speech etc.
- During content creation, basic filtering runs synchronously to catch obvious violations (based on keywords matching or predefined rules). Rate limiting prevents rapid-fire spam and abuse attempts.
- The background processing system conducts deeper content analysis, complementing the real-time checks. When users report content, it triggers a review process that combines automated analysis with human oversight when needed.