
Overview
A Web Crawler (or spider/bot) systematically browses websites to collect information. It starts with a list of seed URLs, retrieves their content, extracts useful information, and discovers additional links for further crawling. Web crawlers are used for tasks such as:
- Building search engines
(e.g.,Google,Bing) - Data collection/analysis (e.g., market research, news aggregation)
- Training large language models (LLMs)
This design focuses on designing the crawler component, specifically for downloading, processing, and storing web pages.
Functional Requirements
- The system starts with seed URLs, and autonomously discovers and crawls new URLs.
- The system should download the web pages from identified URLs,
extract meaningfulcontent (such as text data), and store this information in a structured format for future use. - The system should enable periodic crawling to keep data updated.
- (**)The system should support crawling JavaScript-rendered and dynamic content.
Non-Functional Requirements
- [Scalability]The system should be capable of handling up to 10 billion web pages, with individual page sizes up to 5MB.
- [Performance] The system should complete the crawling of all designated pages within a specified period (days TBD).
- [Compliance | “Politeness”] The system must respect the
robots.txtpolicies of websites to avoid overloading servers. - [Fault Tolerance] The system must be designed to recover gracefully from failures, such as network outages or system crashes, without losing progress.
- [Data Integrity] It should also ensure that data remains consistent after failures.
Below the line
- Authentication & Authorization (protect system from being abused by unauthorized users/admin)
- Subsequent usage with downloaded data (build a search engine: searching + ranking, train LLMs)
High Level Design
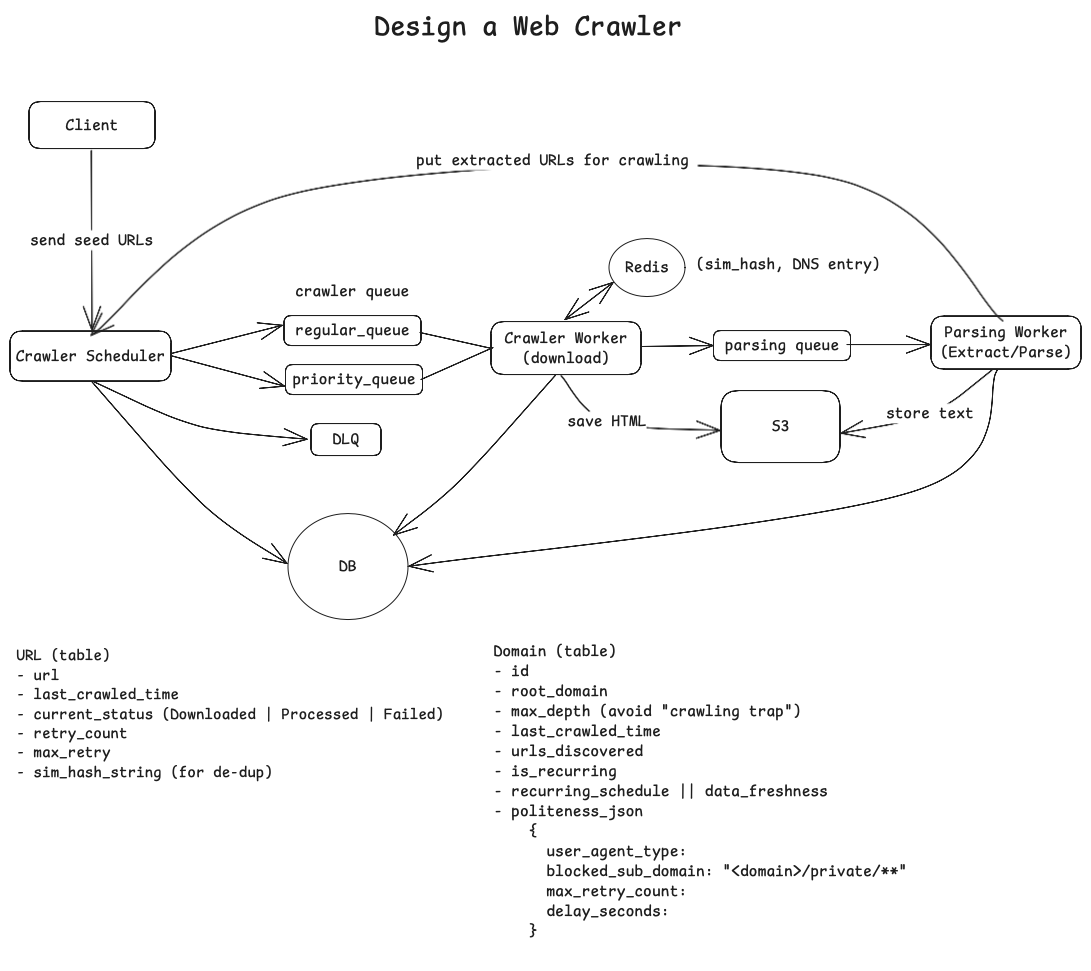
Web Crawling Workflow
- A client submits a crawling request to the system via an API endpoint (e.g.,
POST api/v1/crawl/start). The request includes the seed URLs, the desired depth for crawling, and an optional schedule for recurring crawls. - The [Crawler Scheduler] validates the request and places crawling tasks into appropriate queues. For example, high-priority tasks are placed in a priority queue, while scheduled tasks are placed in a regular queue.
- The [Crawler Worker] fetches tasks from the queue, retrieves the
robots.txtfile for each domain (if accessing it for the first time), and adheres to the domain-specific politeness rules specified in the file. - The [Crawler Worker] downloads the HTML content of the URLs and stores it in S3. It then enqueues a message in the parsing queue to process the downloaded content.
Content Processing Workflow
Before we start, let’s see what needs to be done in this “web crawler” case.
- Request IP for the given URL/domain from local/configured DNS server;
- Fetch/download HTML from target web server using IP;
- Extract text data from the HTML or optionally render dynamic content;
- Store extracted text data into S3 files;
- Put any new linked URLs (extracted from text) to queue for further crawling.
Here is the workflow after adopting above “pipeline processing” approach.
- [Stage 1] [Crawler worker]
- polls crawling messages off from crawling queue and queries the local/configured DNS server to get IP for a given URL.
- downloads the HTML pages from the external web server and stores HTML page in S3 and then publishes parsing request message into parsing queue.
- [Stage 2] [Parsing worker]
- retrieves messages from the parsing queue and reads the corresponding HTML content from S3.
- extracts text data from the HTML, identifies new URLs embedded in the content, and adds these URLs to the crawling queue for further exploration.
Storage
- A Database to store metadata about URLs and domains;
- S3 for saving raw HTML and extracted content.
- An optional Redis cache to store DNS lookups and deduplication hashes for faster processing.
Deep Dive
Handle failures gracefully and resume crawling without losing progress
- Adopt pipeline processing approach and only retry specific stage. Break the crawling workflow into two stages. One for fetching HTML and one for processing HTML. Pipeline processing allows us to isolate failures to a single retry-able stage without losing all previous progress. Also, it allows us to scale and/or optimize each stage independently.
- Retry. Implement exponential backoff retry with a max retry. When crawler worker fails (due to network outage or remote web server unavailable), it updates database by setting URL status to failed. [Crawler Scheduler] schedules a retry based on [1] last_crawler_time and [2] max_retry and puts a new message into crawling queue.
Ensure politeness and not overloading web servers
- The first time when crawling a given domain, crawler worker pulls
robots.textfile and persist requirements into DB (i.e: disallowed domains, frequency, user-agent etc) - [Crawler scheduler] can adhere to all requirements when scheduling subsequent crawling requests.
Make crawler efficient and be able to handle 10 B pages in X days
- Scale up crawler works horizontally based on queue status/metrics (e.g:[1]
ApproximateNumberOfMessagesVisibleand [2]MessageAge) - Dynamically scale up the parser worker (to ensure it can keep pace with crawler);
- Cache DNS results in Redis or employ multiple DNS providers;
- Use
simhashto avoid parsing same HTML page. Hash the content of the page and store it in the DB (URL metadata); When we fetch new URL, we hash the content and compare it to the hashes in the DB. If we find a match, we skip the page. To make the look-up fast, we can build index on hash column. - Use a
max_depthfield to control max depth to avoid crawler traps.