
Overview
What’s are interesting talk points or challenges in designing Uber compared to our last topic — Design Yelp?
- Both require some base domain knowledge on “how to process (store/query) location data”. I.e: find nearby (restaurants vs drivers in this case).
- An unique challenge with designing Uber is “how to manage and process real-time location updates at scale”. Driver will need to frequently report their location in order for the system to do efficient rider-driver matching. So how the system handles heavy writes (location update) and then do efficient matching, is an interesting topic (deep-dive point) for this particular question (and it can not be missed!)
Functional Requirements
- Rider should be able to request a ride with source/destination and get estimates;
- Rider should be able to match a nearby driver within a minimal wait time (< 30 seconds);
- Driver should be able to accept the ride requests and navigate to Rider;
Non-Functional Requirements
- The system should prioritize low-latency for riding matching to ensure quick response times for both driver and rider;
- The system should also ensure strong consistency on rider-driver matching. Specifically
- One ride is not matched to more than one driver at a time;
- One driver does not get assigned with multiple riders at the same time;
- The system should be highly available and minimize downtime, and ensures requests can be processed 7 * 24;
- The system should also be able to handle high throughput during peek hours or events;
Below the line
- Rider & driver rating (review each other)
- Schedule in advance (schedule a pick up with future time)
- Request different type of cars (UberX, UberX Priority, UberShare)
- Change rides (i.e: update drop-off location)
API Design
1. Rider to request a new ride
2. Rider to accept a ride
3. Driver to accept a new ride request
High Level Design
Rider should be able to request a ride with source/destination and get estimates.
To calculate distance and travel time between two location, we can use Google Maps Distance Matrix API. The API takes a request containing origin and destination and transportation method (car, bike etc) and returns travel distance and estimated travel time (in traffic).
With above context knowledge, here is the workflow:
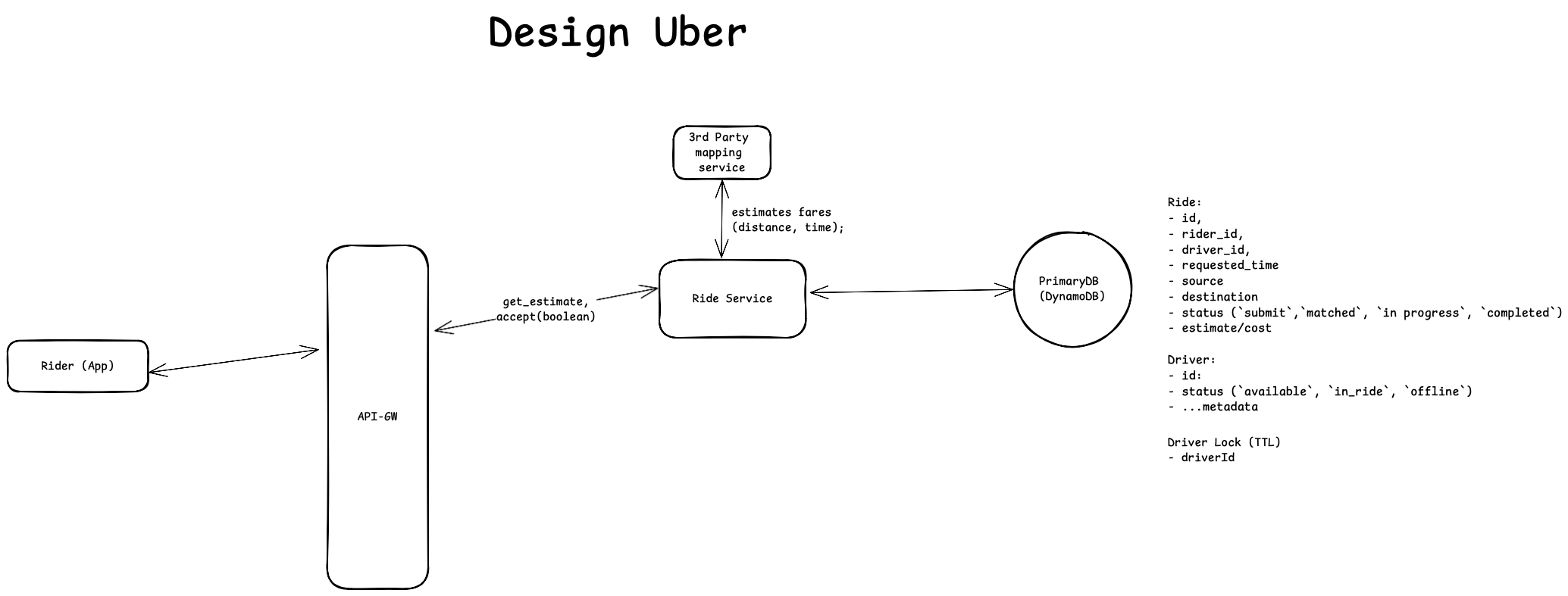
- Rider opens the Uber App and searches for a destination address. Uber app captures rider’s current location though mobile’s system (location service), and then send a POST request to the [Ride service].
- The [Ride service] makes a request to Google Maps Distance Matrix API, providing source and destination coordinates. The API returns [1] the distance between points and [2] the estimated travel time accounting for current traffic conditions. The [Ride service] then calculates the fare based on the returned distance and estimated travel time (using a predefined pricing model). And then it persists the distance and estimated travel time by inserting a new row in the ride table, and finally returns the ride information to the rider, containing the [1] calculated fare, [2] trip distance, and [3]estimated travel time.
Rider should be able to match a nearby driver with a minimal amount of wait time (< 30 seconds);
Driver location is a critical factor in the matching process - drivers and riders should be in close proximity to minimize both pickup travel distance and rider wait times. The initial matching strategy implements a simple proximity-based approach: when a rider accepts the fare, the system queries for all available drivers within a 1-mile radius of the rider's location and sorts them by distance from the rider.
This matching process requires two core services:
Location Service: Responsible for receiving and persisting periodic driver location updatesMatching Service: Handles the complete matching workflow, including:- Querying nearby drivers
- Sending notifications to candidate drivers
- Managing driver acknowledgments
- Notifying riders of successful matches with estimated pickup times
The following diagram illustrates the system workflow with these two services integrated:
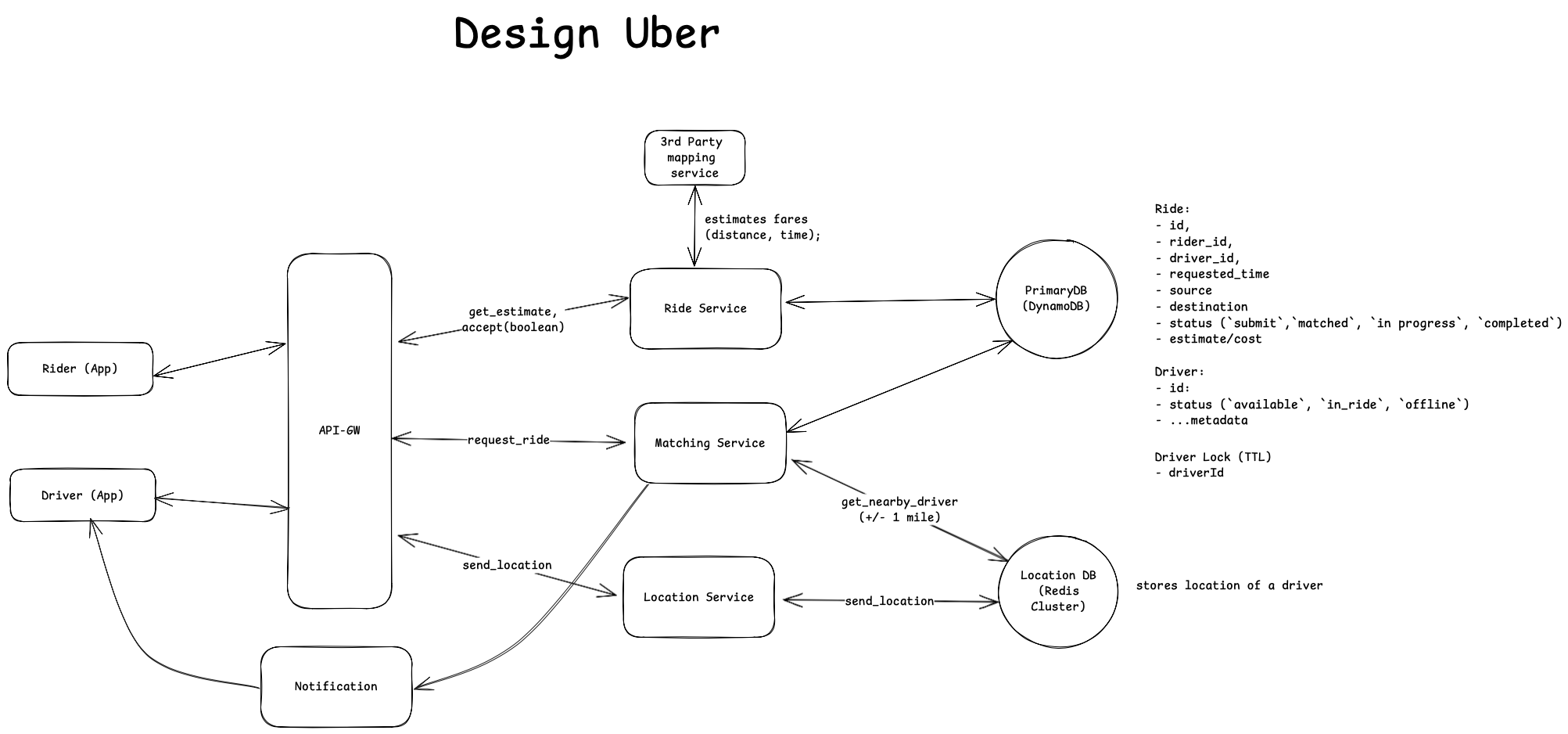
[1] Location Service Workflow
The Location Service handles two main scenarios:
- Driver Session Management
- When a driver starts their shift, they log into the app
- The app sends an initialization request to the Driver Management Service (less interesting in this topic. we just use abstraction name to represent it).
- The Driver Management Service updates the driver's status in the database:
- Sets status to Active or Online when starting.
- Set status to Offline when signing off.
- Location Tracking
- During active hours, the driver app sends periodic location updates
- (Adaptive Location Update) Update frequency varies by context:
- Every 5 seconds in busy areas or during peak hours
- Every 30 seconds in rural areas or during off-peak hours
- Location Service persists these updates to the location database
[2] Matching Workflow:
- Rider sends a PATCH request to accept the ride (after receiving the estimated fare).
- API-GW routes this request to matching service to start matching process. Matching service queries the Location DB for drivers within 1 mile radius of rider (results are sorted by distance to rider).
- (Matching Process) For each available driver (def. “available”: not on ride & no active holds or locks):
- Lock driver record for 10 seconds
- Send ride request notification to driver
- Wait and handle driver response
- On acceptance: Update ride status from 'requested' to 'matched'
- On denial or timeout: Release lock and proceed to next driver. Repeat until successful match.
Driver Locking Implementation
The system requires a locking mechanism to ensure consistent driver-rider matching and prevent multiple ride assignments. Two implementation options are considered:
Option 1. Database Lock Column
- Implementation: Add lock_timestamp column in Driver table
- Driver availability is determined by checking if lock_timestamp is NULL
Option 2. Redis-based Locking (Preferred)
- When matching service wants to lock a driver, it first checks if a lock exists for the driver, and creates lock entry (Key: driver:lock:{driver_id} and Value: {ride_id}:{timestamp} ) with TTL (10 seconds).
Why Redis-based approach is preferred?
- Redis operations are in-memory and extremely fast. It can handle thousands of lock operations per second. And database option requires additional setup (read-only replicas) to make read/write fast;
- Built-in TTL support. Redis will automatically delete the key once TTL is reached.
However, using Redis would add additional infrastructures (Redis cluster). This is relatively minor compared to the benefits especially considering:
- Transient nature of lock operations. (A lock is expected to exist for short amount of time. like 10 seconds). It does not require to persist for long period.
- We have critical throughput requirements for matching service. Separating it/lock out reduces loads on main database.
Database Options for storing drivers’ location data.
We can use [1] PostgreSQL + PostGIS extension or [2] Redis (Geo Hashing) for storing drivers’ location data. Both are greats options in terms of storing GEO location data and handling GEO query (i.e: nearby + radius). To see which one is more appropriate, let’s work backwards from our requirements:
- System Requirements:
- (Scale) As of 2024, Uber has 5.4 M drivers worldwide. (round it to 6M). Among all 6 M total drivers, let’s assume 50% (3M) are active drivers.
- Update frequency: every 5 seconds.
- (QPS) 600 K (Peak: 1.2 M ~ 1.8 M)
- Storage Options Analysis:
- Option 1: PostgreSQL + PostGIS
- Write capacity: 20K-30K GEO operations/second
- Read capacity: 150K-250K queries/second (with 10 replicas)
- Uses QuadTree for spatial indexing
- Option 2: Redis with Geo Hashing
- Write capacity: 250K operations/second per node
- Read capacity:
- 60K simple radius queries/second
- 30K complex queries/second
- Cluster size needed: 6 nodes for supporting 600K QPS
- Uses GeoHash for spatial indexing
- Option 1: PostgreSQL + PostGIS
Redis is preferred for location data storage because:
- Superior write throughput with simpler horizontal scaling
- Automatic TTL management for location data
- Efficient GeoHash implementation for frequent updates (why? PostGIS uses QuadTree while Redis is backed by GEO hashing. QuadTree is really good at handling radius queries but has significant overheads in re-balancing the tree when adding nodes. GeoHash is a better option for handling frequent updates (easy to store and does not require additional data structure)
However, one call-out is the data durability issue with Redis. There is potential data loss during Redis node failures. This is considered as “acceptable” (with mitigations). Why?
- Matching is based on current location. (we don’t care where the driver was 3 month ago?) In other words, historical location data is less important.
- However, losing “current location data” is not okay. It can lead to “inefficient matching” (i.e: driver is actually available. but its location data is not persisted or lost due to Redis node failure). There are recovery mechanism that can be implemented to mitigate node failures (refer to “how to handle potential failures” in deep-dive section)
Rider Update Mechanism
Ride-matching could take some times (between rider sending initial ride request and receiving a match), especially in busy areas or peak hours. So when rider is waiting to be matched with a driver (or waiting for drivers to pick up), it’s important to keep rider updated on the matching process (”found a driver” —> “matching” —> “matching failed” —> “matching another driver” —> “matched” —> “on the way to pick up” —> “picked up” ).
There are two possible approaches to consider
- Option 1: Long-polling. Client (rider app) polls for updates (or checking on matching status).
Matching servciekeeps querying primary DB (ride table) for ride status. - Option 2: WebSocket.
- A persistent connection is established at ride request;
- Server keeps pushing updates for
- Matching attempts
- Driver assignment
- Pickup ETA updates
- etc…
WebSocket is an preferred option in this case. Why?
- Real-time requirements:
- The matching process requires frequent updates (found driver —> matching —> matched —> on the way etc).
- Drivers’ location need to be shown in real-time on the rider’s map (for a better user experience. Rider knowns diver’s real-time location and ETA).
- All those updates should happen with ideally minimal latency;
- Problems with Long Polling:
- Creates unnecessary server load since the client must repeatedly request updates. And each poll requires a new HTTP connection, adding overhead.
- Can lead to delayed updates due to the polling interval.
- More complex error handling on polling (timeouts, retries etc).
- WebSocket Advantages:
- Single persistent connection instead of multiple HTTP requests.
- Server can push updates immediately when updates happen.
- More efficient use of server resources (i.e: avoid unnecessary DB queries).
To summarize, WebSocket is a better choice in this case because it can easily handle multiple type of updates (driver location, ETA, ride status) over the same connection in near real-time (when those updates happen). However, there is also a notable drawback of WebSocket — needing to maintain persistent connections (i.e: using WebSocket server/manager). The benefits far outweigh this concern for Uber's real-time requirements.
Driver can accept the ride requests and navigate to Rider;
Background knowledge — how to get turn-by-turn navigation information between two locations? For turn-by-turn navigation, we can use Google Maps Directions API [link], which takes origin and destination address and returns the most efficient routes when calculating directions.
With above context (knowledge), here’s the detailed workflow.
- Driver accepts a ride requests by sending PATCH request to backend (Matching service) along with their current location.
-
- Matching service updates ride information (status, driverId) in ride table and then sends request to Google Maps Directions API service providing origin (driver’s current location) and destination (rider’s location). The API returns a turn-by-turn navigation information (in json) format. Matching service can then send back navigation information.
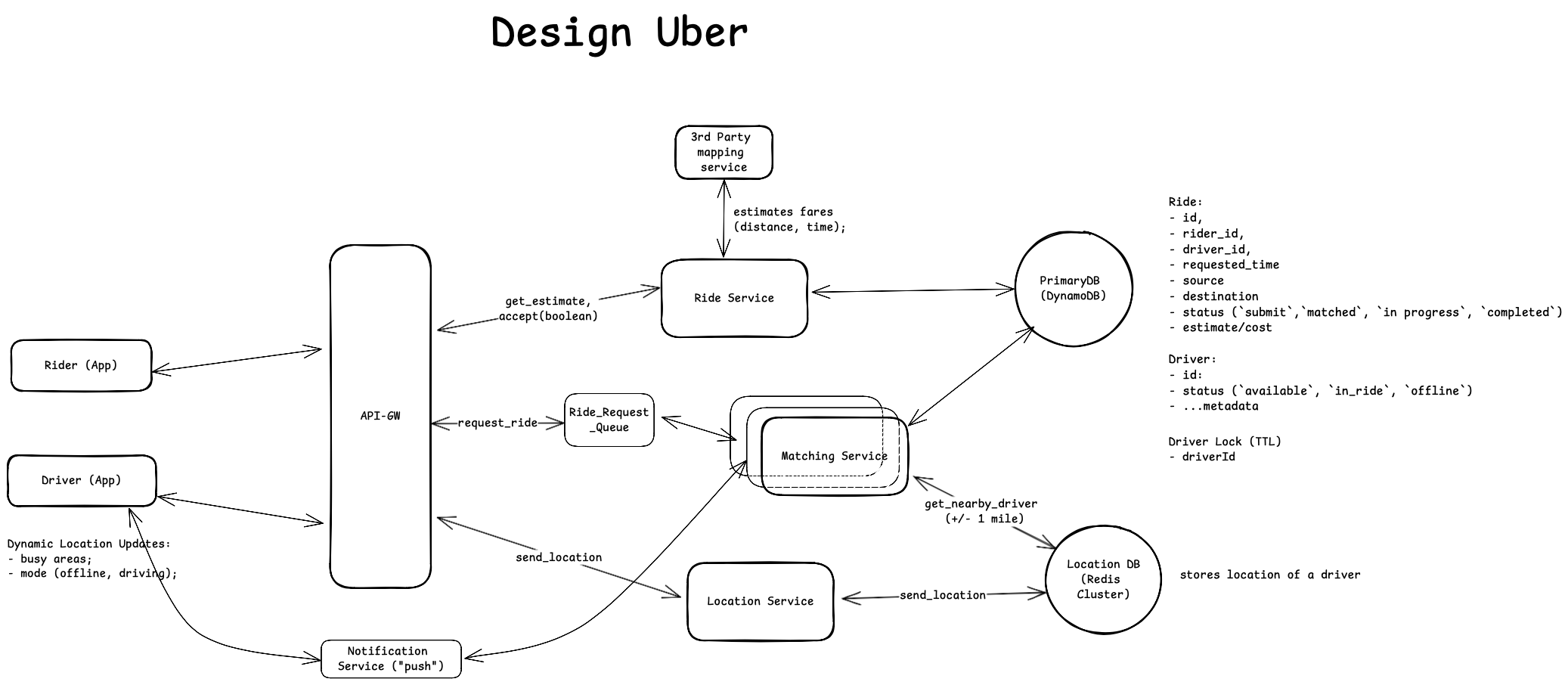
(Wrap up) The final Design Diagram with everything we discussed:
Deep Dive
Prioritize low-latency for riding matching
Using Redis to store drivers location.
Redis’s GEO support is backed by GEO hashing while PostGIS is implemented based on QuadTree.
- QuadTree excels at handling “relationship query” such as “containment, intersection”. For example, in the Yelp case, for query like — “find all Thai restaurants in downtown SF”, QuadTree will be fast and hence recommended.
- GeoHashing is efficient for radius queries. For example, find “nearby” (1 miles of my current location) drivers. Why? For query "find drivers within 1 mile of (37.7749, -122.4194)":
- converts center point to geohash (37.7749, -122.4194 —> “9q8yyk”);
- calculates neighbor boxes that could contain points within radius based on “prefix”.
- (after getting all geohash boxes) examines/filters geo points by their distance.
- This process is faster compared to QuadTree because QuadTree needs to traverse the tree recursively (in order to answer a range query — 1 miles within a specific geo point). And GeoHashing is based on “simple string prefix matching”. In addition, Redis stores Geohahes using a sorted set so that it takes O(logn) time to find/search “neighbor” boxes.
Ensure strong consistency on rider-driver matching.
We introduced redis-based locking mechanism to achieve strong consistent on rider-driver matching (no double-booking for drivers, no multiple ride assignments). Let’s break it down on how it works.
- Single Source of Truth — DB
- Primary database ride table maintains ride and driver status
- All state changes must be committed here first
- Redis locks are transient and only for coordination (matching)
Handle high throughput during peek hours or events;
- (Within the same instance) Partition data by city to reduce per-node data volume.
- To ensure the system does not lose any requests during peak hour, we could also consider placing a queue between API-GW and matching service. Then we set monitors on queue size and dynamically scale other components (matching service , redis cluster node).
Highly available and minimize downtime
- Multi-Region Deployment + Failover. Each region handles local traffic primarily and failover traffic as needed. We deploy Uber backend system in multiple geo locations (us-east-2 and us-east-1). In case one region goes down, we can failover all request to the other region.
- Handle Redis node failure.
- Enable Redis Sentinel to configure automatic failover (when there is a node failure);
- Enable AOF (Append-Only File) to periodically save the in-memory data to disk. So that we can recover from data loss (when node goes down);
- Handle component failures. (matching service goes down, location service goes down etc)
- Implement server monitoring to collect key metrics (resource utilization, queue size, latency) to effectively monitor service healthy
- Perform failover when a service instance goes down;
- Handle external API failures. (Google Map APIs for fare estimation and route planning)
- Monitor API health (i.e: failure rates, latency).
- (In case API is just completely unavailable or there is a network outage, so that we could no longer get distances, routes from Google Map APIs) We could implement following failback mechanism:
- Cache recent fare estimates for similar routes
- Use straight-line distance calculation as backup
- Predefined base fare + distance multiplier