
Functional Requirements
- Users should be able to view a stream of posts from people they follow (with the most recently created posts at the top).
- (support pagination) Navigate through feed content using pagination, viewing 20 posts per page, accessing older content through infinite scroll or pagination controls
Non-Functional Requirements
- The system should be fast in serving view_feed requests. (p90 < 500 ms)
- The system should be highly available in serving requests (99.99 uptime)
- The system should be scalable to support X users/posts (TBD)
- The system can adopt eventual consistency when generating newsfeed. (New posts should be generated into feed in less than 1 minute)
- The system should be fault tolerant in handling component/infrastructure failures
Below the line
- Feed personalization/recommendation through user behavior analysis
API
request a feed
High-level Design
Generate Newsfeed
To build a scalable newsfeed system, we'll explore three approaches, evolving from a simple solution to an optimized solution that satisfies all of non-functional requirements.
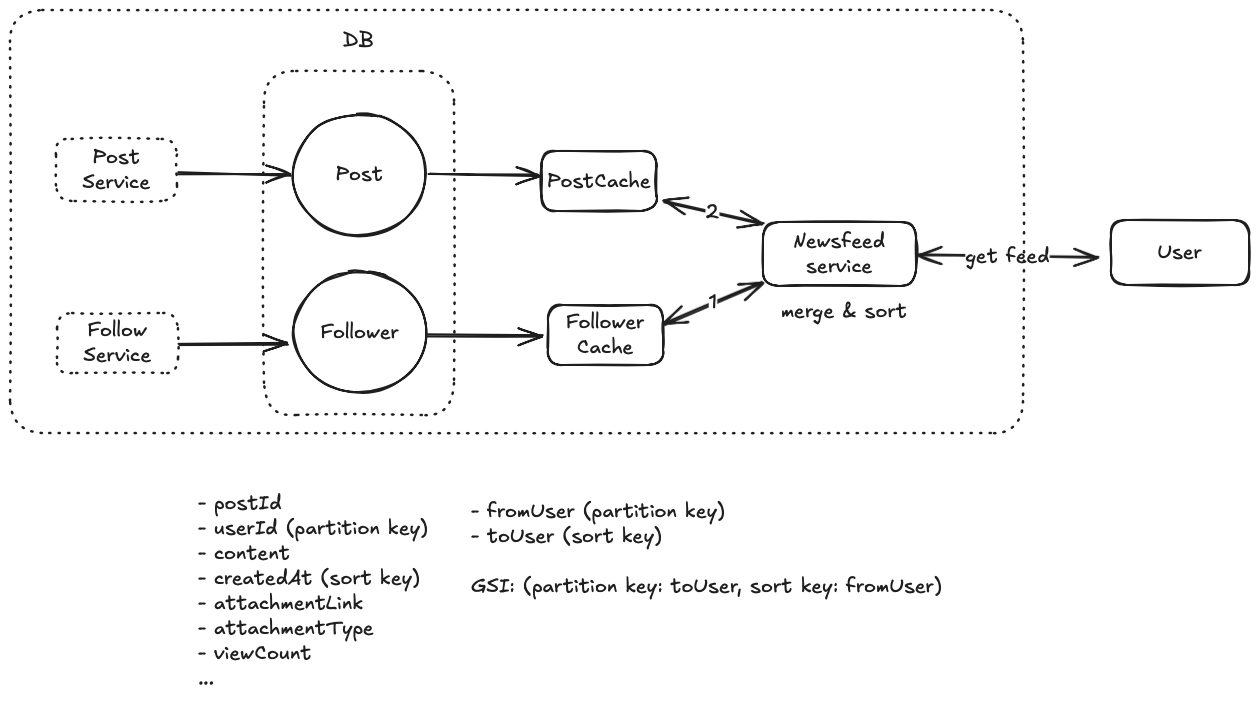
Solution 1: Simple Pull Model (Fanout-on-read)
When a user requests their feed, the Newsfeed Service performs three operations:
- Retrieves the list of users they follow through the Follower Service
- Fetches recent posts from each followed user through the Post Service
- Merges and sorts these posts by creation time before returning them
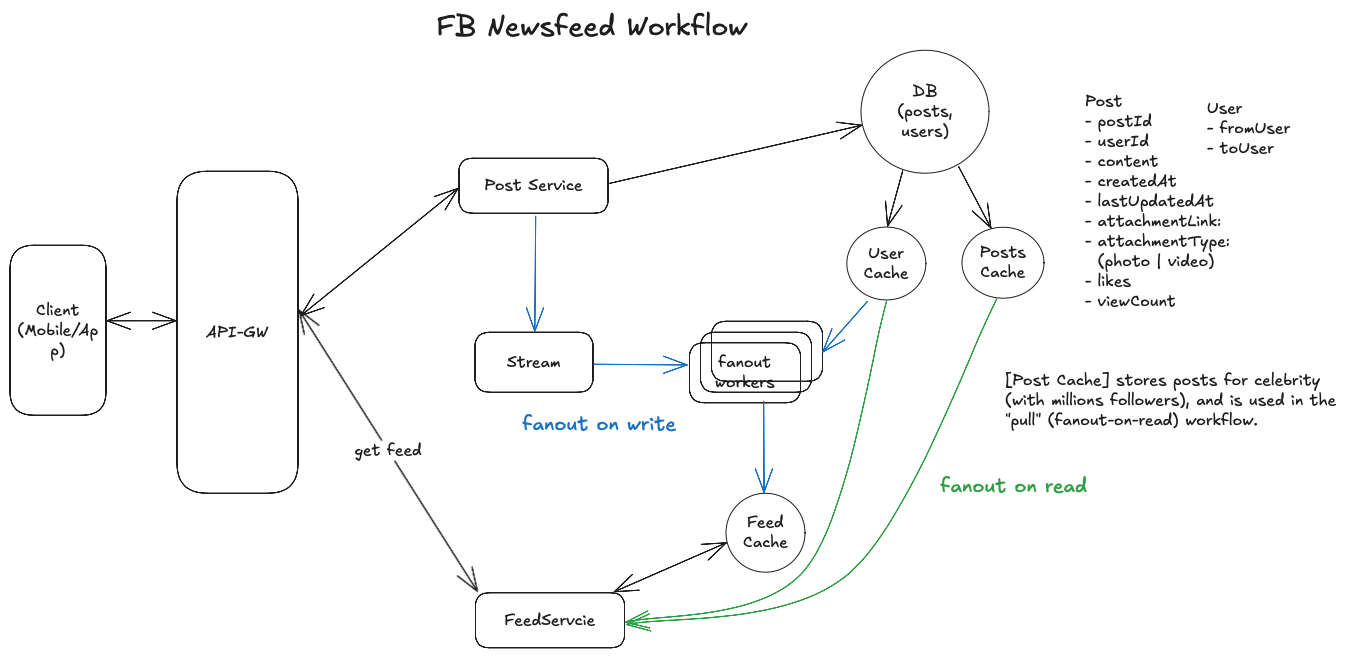
And here is the workflow diagram for solution 1.
To further reduce latency and system load on generating feeds, we can use a technique — pre-compute or create feeds offline adaptively.
With all improvements (database index + cache + pre-compute), this option works but does not scale (at Facebook or Twitter level). Why?
- Facebook has 1B DAU. Assume each user on average opens app (or requests newsfeed) 1 ~ 5 times a day. QPS (on newsfeed request) is 10K ~ 50 K per second. Our pre-configured read capacity on dynamoDB can not catch up on this read workload (resulting in read throttling exceptions). Even we could further increase read capacity on dynamoDB, this creates a significant read workload on DB.
- New posts are required to be generated in newsfeed within 1 minute. To stick with 1 minutes requirement and ensures cache is also populated with latest (last 1-minute) data, there will be lots of database polling even when there could be no change on post (or no new posts).
To address those challenges, we introduced solution 2 — Fanout on write (”the push model”).
Solution 2: Fanout on write (Push Model) + Write feed in DB (cache)
Different from fanout-on-read (where the feed generation request fans out to fetch posts from all users the given user follows), fanout-on-write pushes the new post content to all followers. Following diagram explains the workflow for fanout-on-write.
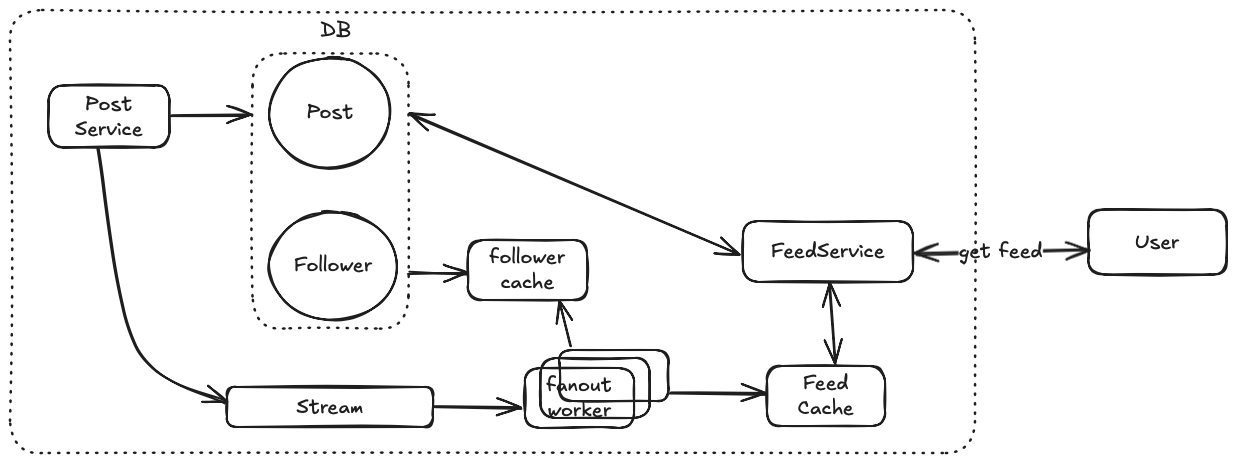
- When [Post Service] processes a new post request, it writes new post to DB and also publishes a new post creation message to a message queue (AWS Kinesis Stream || Kafka).
- Fan-out process:
- [Fanout worker] consumes the message from the queue and retrieves the list of followers or the post’s author from follower cache.
- [Fanout worker] directly writes to feed cache for each follower (for fast retrieval).
- When a user opens the app or requests a new feed, the [Feed Service] retrieves the pre-computed feed from feed cache and returns the feed to user. Pagination is handled through cursor-based navigation of the cached feed.
Benefits and Drawbacks (of solution 2)
The benefit of this fanout-on-write process is that the users don’t have to go through their friend’s lists to acquire newsfeeds. In this approach, the number of read operations is significantly reduced. However, this approach introduces new challenges, particularly the “celebrity problem” where users with millions of followers create massive writes.
[Preferred] Solution 3: Hybrid Approach
Our hybrid approach combines the advantages of both pull and push models to create a scalable and efficient newsfeed system. The key insight is that different types of users require different feed generation strategies. We can classify users into three categories based on their characteristics and applies distinct newsfeed generation strategies for each:
- Regular users (with less than 5 K follower) — fanout-on-write
- For regular users with moderate follower counts (less than 5K followers), we employ the fanout-on-write approach. When these users create posts, the system immediately distributes them to their followers' feeds, ensuring quick access and optimal read performance for the majority of our user base.
- Celebrity accounts (with 5K or more followers) — fanout-on-read
- For celebrity accounts that have massive follower bases (5K or more followers), we switch to a fanout-on-read strategy. This prevents the system from being overwhelmed by the write amplification that would occur if we tried to update millions of follower feeds simultaneously. When users request their feeds, the system dynamically merges celebrity posts with their pre-computed feed content, striking a balance between performance and system resources.
- “Cold users” (who haven’t logged in for more than 30 days) — “generate next time when they login”
- The system also optimizes for cold users – those who haven't accessed the platform for more than 30 days. Instead of continuously updating feeds for inactive users, we generate their feeds on-demand when they return to the platform. This approach significantly reduces unnecessary computation and storage costs while maintaining a good user experience for returning users.
In summary, to support this hybrid model, we implement a dynamic feed generation service that works as follows: When a user requests their feed, the service first retrieves their pre-computed feed containing posts from regular users they follow. It then augments this feed by fetching and merging recent posts from any celebrity accounts they follow. The final feed is sorted by timestamp before being returned to the user.
And here is our final design with everything discussed so far!
Deep Dive
The system should be fast in serving view_feed requests (P90 < 500 ms)
We achieved a fast feed retrieval performance through a combination of (1) pre-computation, (2) caching and (3) content delivery optimization with CDN.
- Feed pre-computation combined with an effective caching system. For most users, their feeds are pre-computed and stored in the feed cache with a TTL of one minute, aligning with our consistency requirements. When a user requests their feed, the Feed Service first checks this cache, providing sub-millisecond response times for cache hits. For celebrity content that isn't pre-computed, we implement a separate caching strategy. Celebrity posts are stored in a dedicated cache with longer TTL values, as these posts typically have higher view counts and longer relevance periods. When generating feeds that include celebrity content, the system performs parallel retrievals, merging pre-computed feeds with celebrity content while maintaining our latency targets.
- CDN Integration. We can leverage CDNs to further optimize content delivery across different geographical regions. The system stores frequently accessed content, particularly media attachments and celebrity posts, in CDN edge locations. When a user requests their feed, the CDN serves static content from the nearest edge location, significantly reducing latency for users across different regions. This is particularly effective for celebrity content that gets accessed frequently across various geographical locations.
The system should be highly available in serving requests (99.99 uptime)
- Service-Level
- For each micro-service (post service, feed service etc), we can deploy multiple service instances and setup monitoring with automatic failover capabilities.
- In addition, we can employ load balancer to distribute traffics across service instances, automatically routing requests away from unhealthy instances.
- Database & Cache Layer
- For database, we propose to use AWS DynamoDB, which is fully managed database service where data is replicated asynchronously across multiple AZs (availability zones). So that data is always accessible through other AZs when one AZ fails.
- For Caching Layer (Redis), we can enable master-slave replication where master node handles write operations while multiple slave nodes maintain synchronized copies of the data. For fault tolerance, we implement automatic failover mechanisms. Each Redis cluster runs a sentinel process that continuously monitors the health of master and slave nodes. If a master node fails, the sentinel orchestrates an automatic failover process: it promotes one of the healthy slave nodes to become the new master, updates the cluster configuration, and ensures all other nodes recognize the new master. This process typically completes within seconds, minimizing disruption to the service.
The system should be scalable to support X users/posts.
Assume we have 1 B DAU and each user requests feeds 5 times a day, then our QPS is 10^9 / 10^5 (seconds in a day) * 5 = 50 K. To support approximately 50 K QPS, we can implement scalability at every layer:
- Service-level scaling. Both post service and feed service scales horizontally. We can dynamically provision and add more service instances based on existing resource utilization, processing latency, incoming traffics.
- Data Storage Scaling. See our previous design on how to scale dynamoDB read/write capacities.
- Caching Layer (Redis) Scaling. The primary scaling mechanism involves adding more nodes to the cluster, with a clear separation of write and read responsibilities. Master nodes handle all write operations, ensuring data consistency, while multiple slave nodes serve read requests. This architecture allows us to scale read capacity by adding more slave nodes as read traffic increases.When write throughput becomes a bottleneck, we implement horizontal sharding across multiple master nodes. Each shard handles a subset of users based on a consistent hashing strategy, allowing us to distribute write load evenly. As the system grows, we can add new shards to accommodate increased write volume while maintaining performance.