
CI/CD isn't just another tech buzzword - it's the backbone of modern software development that keeps your team shipping fast without breaking things (well, most of the time! 😅). In the beginning, let’s first check what CI/CD means:
CI (Continuous Integration) - Your Code's Quality Guardian
Think of CI as that super diligent colleague who checks everyone's work before it gets merged. Every time someone pushes code:
- Code gets automatically integrated into the main branch
- Tests run immediately to catch bugs before they spread
- Fast feedback loops mean developers know within minutes if they broke something
It's like having a 24/7 code reviewer that never gets tired or grumpy!
CD (Continuous Delivery/Deployment) - Your Release Automation Hero
Now this is where things get exciting:
Continuous Delivery keeps your code in a "ready-to-ship" state at all times. Think of it as having your product always dressed up and ready for the party, but you still decide when to actually go.
Continuous Deployment takes it a step further - every change that passes your tests automatically goes to production. It's like having a fully automated assembly line that just keeps churning out releases.
Functional Requirements
Automated Testing PipelineEvery code change should trigger a comprehensive test suite - unit tests, integration tests, and those end-to-end tests that simulate real user behavior. No more "it works on my machine" excuses!
Automated Deployment WorkflowCode that passes tests should flow seamlessly to staging and production environments. Manual deployment steps? Ain't nobody got time for that!
Versioning and Rollback SupportTrack every deployment and make it stupid-easy to roll back when things go sideways (because they will).
Non-function Requirements
Correctness in Build
- 100% Correctness in Build Order (Especially in Monorepos or Multi-Service Architectures)
- Conflict Resolution (Merges, Race Conditions, and Artifact Collisions)
- Consistency Across Environments
Scalability for Growing Teams
- Support 500+ concurrent builds without slowing down
- Median build time should be under 10 minutes for tight dev loops.
- 95th percentile latency should stay ≤15 minutes, even under peak load
- Build agents must auto-scale within 30 seconds to handle traffic spikes.
Multi-Tenant Isolation and Fairness
- Each tenant’s secrets, logs, artifacts, and environments must be isolated and access-controlled.
- No tenant should exceed 25% of system-wide runners unless capacity is idle
- Avoiding duplicate jobs ****and fair resource sharing
High Level Design
FR1: Automated Testing Pipeline - The Quality Gate
Let's dive deep into the first major functional requirement. When a developer pushes code, magic should happen automatically:
- Unit tests – check isolated functions/modules
- Integration tests – check how components work together
- End-to-End (E2E) tests – simulate real user flows via UI/API
Triggered on every pull request or code push, end to end flow can be shown based on diagram below:
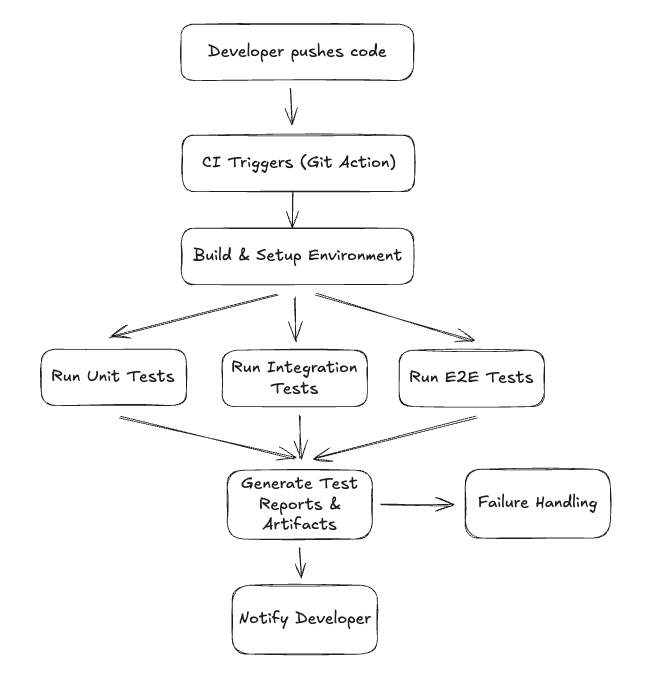
Here's what happens behind the scenes:
- Developer pushes code to GitHub (or another supported Git provider).
- Pipeline scheduler parses the config (e.g.,
.yaml) and prepares job definitions. - Build & test environments are spun up in isolated containers or virtual machines.
- Unit tests execute in parallel to quickly validate low-level correctness.
- Integration tests run to verify service and component interactions.
- End-to-end (E2E) tests execute in a realistic environment simulating user behavior.
- Test results and build artifacts are generated and stored for debugging or deployment.
- Developers are notified via GitHub status checks, Slack, or email with detailed feedback.
- Failure Handling (if a job fails):
- The pipeline marks the build as failed, and all downstream dependent jobs are skipped or halted.
- A detailed failure report is attached to the CI interface and status checks (e.g., in GitHub PRs).
- Logs and artifacts from failed steps are preserved for inspection (e.g., stack traces, stdout, screenshots from E2E tests).
- Alerts or notifications are sent via Slack, email, or webhook to the relevant team or developer.
- The system supports "Retry failed step" or "Rerun pipeline" actions—ensuring idempotent re-execution without redundant work.
- Developers are notified:
- GitHub status checks are updated (e.g., ✅ or ❌ on the PR).
- Slack or email alerts include a summary of which stage failed, why, and links to logs and rerun options.
In high-level system design interviews, it's not just about knowing the right components — it's about how you connect the dots. A clear and structured data flow isn't optional — it's your secret weapon. It shows that you can think like an architect, communicate like a leader, and build like a seasoned engineer.
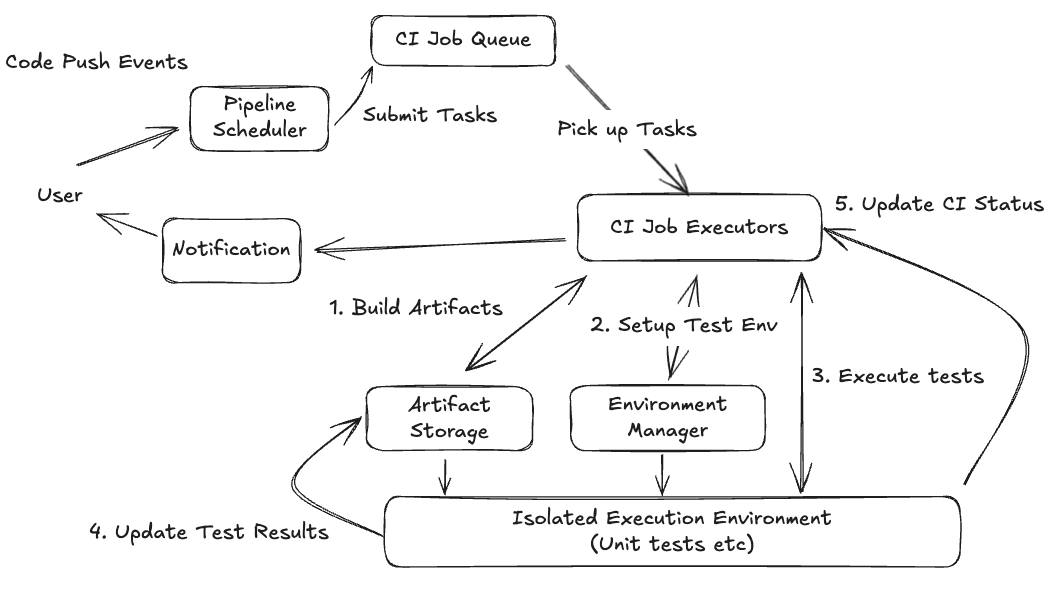
At a high level, CI systems adopt an event-driven and queue-based orchestration architecture. Many design principles overlap with other asynchronous workflow systems—such as web crawlers or task queues in platforms like LeetCode. Common discussion topics like retries, idempotency, and failure handling are widely applicable but will be discussed here for brevity.
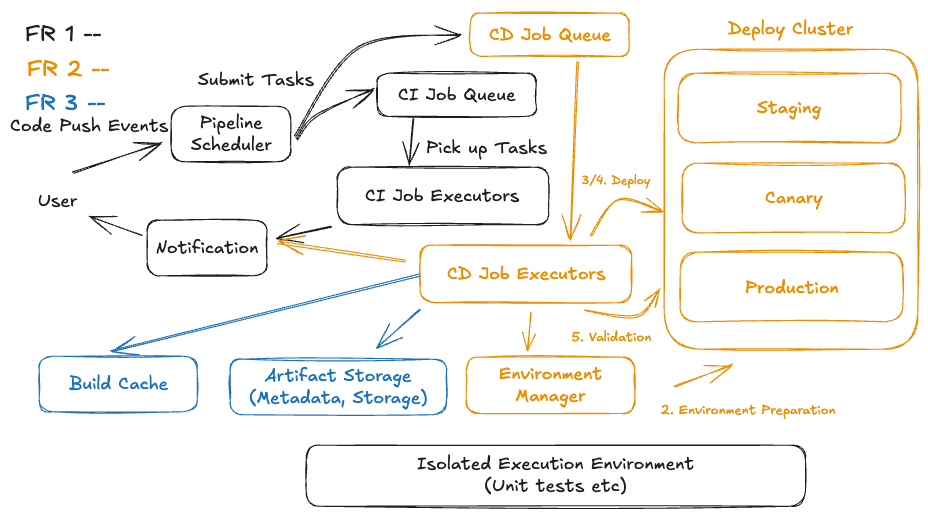
FR2: Automated Deployment Workflow:
Once the CI stage has successfully built and packaged the artifact (e.g., a .jar, .zip, Docker image, etc.), the CD pipeline takes over. Here's how it typically proceeds:
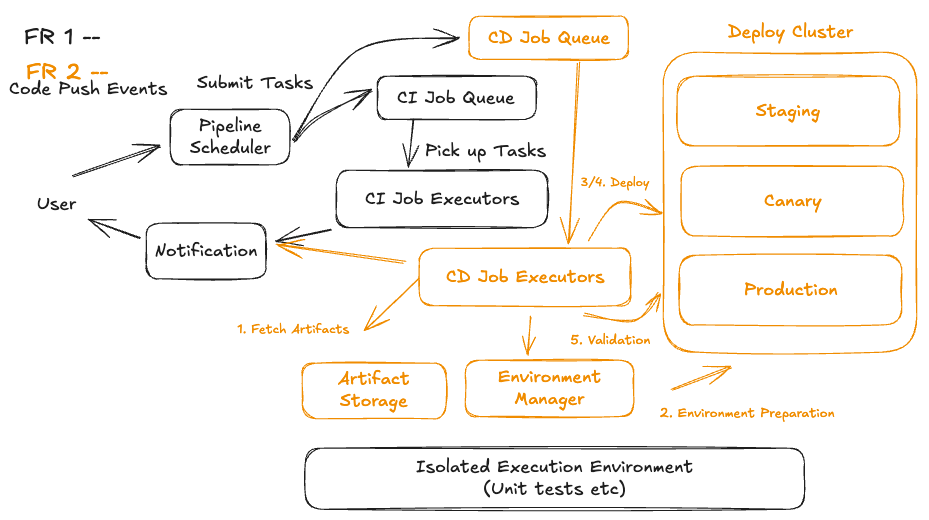
Let us see how a Staff Engineer at Meta might explain this Continuous Deployment (CD) flow in a system design interview, focusing on clarity, precision, and tradeoffs — the kind of framing you'd expect from a high-level engineer who designs and operates large-scale deployment infrastructure:
FR3: Artifact Management
Let’s talk about artifact versioning, which you might have heard multiple times. With big scale, where thousands of services deploy dozens of times per day, you can't afford ambiguity in what you're deploying. Versioning gives us predictability, rollback, and auditability — all critical for system integrity and developer velocity.
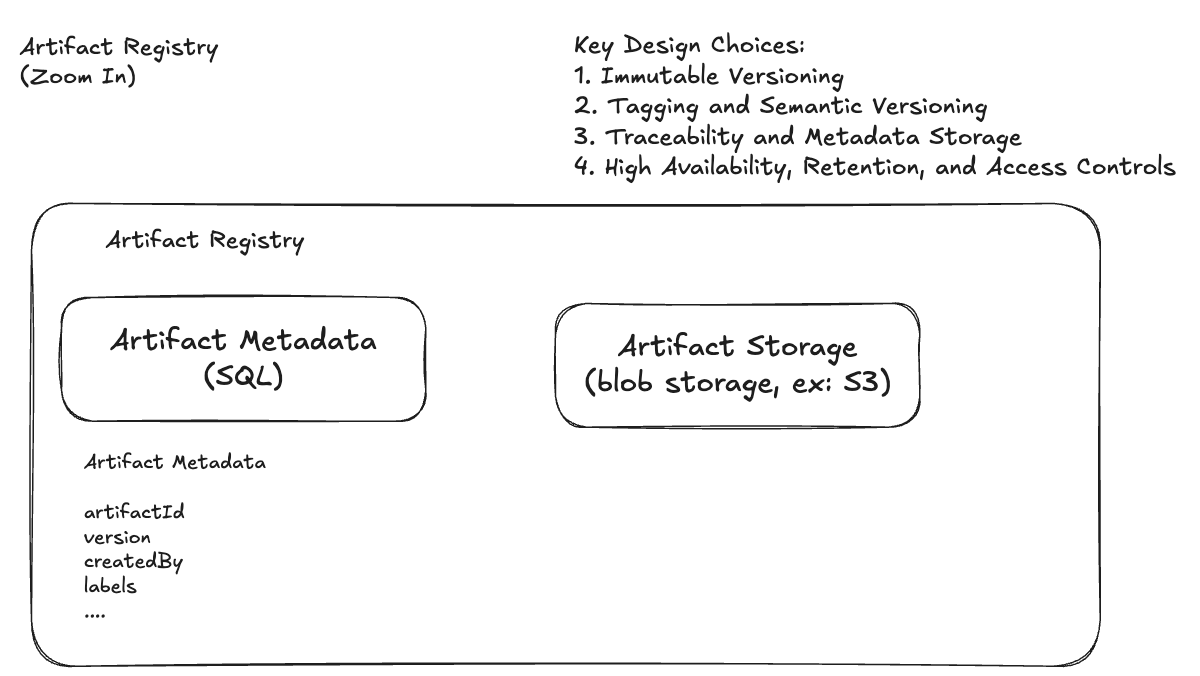
Artifacts is treated as immutable build outputs — they’re the truth of what gets deployed, not the source code. If something breaks in production, we want to know exactly which artifact was running, not just which Git commit was merged.
So we follow a few principles:
- Artifacts are immutable. Once built and tagged, they’re never changed.
- Deployments are traceable. We can correlate a version in production to a Git commit, build run, and test results.
- Rollbacks are instant. We don’t rebuild — we redeploy existing artifacts.
These principles rely on metadata-driven deployment to work effectively. Immutable artifacts require metadata to indicate their environment readiness, test status, and approval without modifying the artifact itself. Traceability and instant rollbacks depend on metadata to track artifact lineage and safely redeploy previously validated versions without rebuilding.
Metadata-Driven Deployments
Every artifact published to our internal registry carries rich metadata — not just build info, but changelogs, test coverage, commit hash, and even the results of static analysis or security scans. Here's a simplified example:
This metadata powers multiple workflows:
- Auto-promotion to production if quality gates pass
- Easy rollback by querying for previous 'prod-approved' artifacts
- Audit trails for every deployment
Deploy Rollback
Rollback is treated as a first-class, deliberate operation—not a hack or manual override. When a deployment introduces a regression, bug, or performance issue, we don't rebuild or patch the code—we redeploy a previously built, versioned artifact that is already known to be stable.
For example:
This command simply tells Kubernetes to point to a previously tagged Docker image, such as v1.1.0, which has already been tested and deployed successfully. Because all artifacts are immutable and stored in a registry with metadata, the rollback is instant—usually within 30 seconds—and risk-free, since no new code is being introduced.
But rollback isn’t just about reverting code quickly. It’s also about operational safety and visibility:
- The rollback is logged and versioned as part of the deployment history.
- Alerting systems and dashboards are annotated with rollback metadata (e.g., who triggered it, what version was restored, and why).
- Slack or email notifications are sent to relevant teams and on-call engineers.
- Rollback events are correlated with metrics and incidents to give downstream systems and teams full context.
This ensures not only speed and reliability, but also traceability and transparency, allowing your organization to recover quickly and learn from failures without chaos.
You might already know how to design a CI/CD pipeline—but have you figured out how to optimize resource usage, ensure consistent builds, and handle race conditions effectively? If not, let’s dive in.
Deep Dive
Deep Dive 1: Scalability for Growing Teams
At a high level, CI/CD systems are a textbook example of asynchronous, event-driven architecture. They rely heavily on queue-based orchestration, where events like code pushes or merge requests trigger downstream pipelines—mirroring the design patterns seen in some of the most popular async systems, such as web crawlers, job schedulers, and task queues used in platforms like LeetCode. All scalability method can be directly applied to CI/CD pipelines, we will dive deeper into it.
As engineering teams expand—from tens of engineers to hundreds or even thousands—the CI/CD system must evolve to keep up. What once worked for a single service or a handful of developers now needs to support dozens of teams, thousands of daily commits, and hundreds of concurrent builds. Under this load, even well-architected systems begin to show stress. The first cracks typically appear in three critical areas:
- Resource Contention – when jobs compete for limited build resources
- Artifact Storage Explosion – as thousands of builds generate terabytes of data
- Duplicate or Redundant Builds – which waste compute and delay feedback
These aren’t just nuisances — they slow down iteration, bloat infrastructure costs, and frustrate engineers who are stuck waiting for builds or debugging flaky pipelines. Let’s break down each problem and see how scalable systems overcome them.
- Resource Contention → Smart Scheduling & Prioritization
As your team grows, so does the frequency of pull requests, test runs, and release pipelines. If your CI system assigns all jobs with equal priority, high-priority tasks (like hotfixes or release builds) get stuck behind trivial or low-impact jobs. Developers lose productivity, and urgent fixes get delayed.
To address this, a scalable CI/CD system introduces priority-aware scheduling, where each job is evaluated based on metadata like:
- Branch type (
main,release/*,hotfix/*vs.feature/*) - Code diff size or criticality
- User roles (e.g., tech leads vs. junior contributors)
- Job type (e.g., release pipeline vs. nightly build)
Instead of treating the queue as first-in-first-out (FIFO), jobs are inserted into a priority queue, implemented using tools like:
- Redis sorted sets – ideal for ranking jobs by dynamic priority
- RabbitMQ with priority support – for message-based queues
- In-memory heaps – for performance-critical custom queues
Once prioritized, jobs are dispatched to workers by a smart scheduler, which optimizes throughput using techniques such as:
- Bin Packing – maximize utilization by assigning multiple light jobs to underused runners
- Fair Scheduling – prevent resource starvation by ensuring all teams get fair access
- Backpressure & Throttling – delay non-urgent builds when system is under load
This model ensures the system can scale linearly while delivering fast feedback for critical jobs and maintaining fairness across all teams.
- Artifact Storage Explosion → Caching & Retention Policies
Modern development practices like microservices, containerization, and full-stack builds cause CI/CD pipelines to generate enormous volumes of data — often gigabytes per build, multiplied across hundreds or thousands of builds per day. Without proper controls, this leads to:
- Disk bloat from accumulated Docker layers and build logs
- Repeated downloads of the same third-party packages
- Pipeline delays due to redundant compilation steps
To tackle this, successful CI/CD systems rely on a combination of caching, reuse, and cleanup. The core strategies include:
- Dependency Caching: Prevent repetitive downloads by caching package installs (e.g.,
.m2,node_modules,pip) - Docker Layer Caching: Reuse previously built layers unless changes are detected
- Remote Build Caches (like Bazel or Gradle Cache Server): Share compiled outputs across pipelines or even teams
- Incremental Builds: Only recompile or retest the parts of the code that actually changed
- Retention Policies: Automatically delete logs, artifacts, and caches that are stale or unused
Together, these strategies significantly reduce infrastructure spend, storage complexity, and pipeline execution time—without sacrificing build correctness or reproducibility.
- Duplicate Builds → Deduplication & Event Coalescing
In fast-moving engineering environments, it’s common for developers to:
- Push multiple commits in quick succession
- Accidentally trigger the same pipeline multiple times
- Retry flaky jobs that didn’t fail for real reasons
If the CI/CD system treats each trigger as unique, this leads to wasted compute, longer queue times, and chaotic logs. That’s where deduplication comes in.
A robust CI system should intelligently cancel outdated jobs when superseded and avoid running identical jobs that offer no new value. This is known as event coalescing. Some best practices include:
- Fingerprinting builds: Create a hash of commit SHA + pipeline config. If it already exists, skip.
- Debouncing triggers: Wait a few seconds before acting on incoming webhook triggers to batch related events.
- Locking or deduplication keys: Use Redis, etcd, or SQL row locks to ensure only one build runs per commit.
Deep Dive 2 - How do modern build systems ensure correctness in build execution?
In any CI/CD system, correctness in build means that:
- Changes are detected accurately — the build system tracks inputs like source code, dependencies, and config to rebuild only when necessary.
- Dependencies are honored — components are built in the correct order based on declared relationships, avoiding race conditions and stale builds.
- Builds are reproducible — consistent environments and deterministic behavior ensure the same result across machines and runs.
- Previous work is reused when possible — caching mechanisms avoid redundant computation by reusing unchanged build outputs across users and machines.
Achieving this in practice requires more than bash scripts or Makefiles — it demands a declarative, dependency-aware build engine. That’s why we use Bazel as a concrete example to demonstrate how correctness is enforced in real-world, large-scale CI/CD systems.
Bazel doesn’t just 'run scripts in sequence' like traditional CI systems. It builds a precise DAG of all targets and their declared dependencies. That DAG dictates the build order automatically.
From the example above, let’s say you’re building my_app which depends on lib_auth, which depends on core_utils. Bazel enforces that core_utils builds first, then lib_auth, then my_app. If you forget to declare a dependency — Bazel errors out. That’s intentional: correctness comes before convenience.
Smart Change Detection
In growing codebases, naive rebuilds waste time and can introduce subtle bugs. Bazel watches everything that might affect the outcome of a build — including:
- Source files
- Dependency code
- Build flags and toolchains
- Compiler versions
It generates fingerprints (hashes) of all inputs. If anything changes, Bazel rebuilds only the affected targets. If nothing changed, it skips the rebuild entirely. This means faster builds and fewer risks of using outdated code.
Bazel vs CI Pipelines
A lot of CI systems run step-by-step scripts. But with Bazel, it’s smarter than that.
Bazel builds a dependency graph (like a flowchart) that shows:
- What needs to be built first
- What depends on what
- What tests can run in parallel
So in CI:
- The build order is automatic, based on real dependencies
- Tests only run after all needed pieces are ready
- Deployments use artifacts (build results) that are verified and locked, so no surprises later
Same Build Everywhere
Bazel runs every build in a sandboxed environment, which are generated by Enviroment Manager. That means:
- It doesn’t use anything weird from your computer
- Every build is clean and predictable
- What works in CI also works on your laptop, bit for bit
Bazel Remote CacheIf someone on your team has already built a component and nothing has changed, Bazel will reuse the result from the cache instead of rebuilding it. This works across machines, improving build correctness while also saving time and compute resources.
Deep Dive 3 - How to build a multi-tenant ci/cd system?
In a multi-tenant CI/CD system, a critical architectural decision is determining what to share across tenants and what to isolate. Shared components—such as build agents, artifact storage, logging infrastructure, and scheduler queues—help optimize resource utilization and reduce operational cost. However, to ensure security, reliability, and tenant independence, it's equally important to isolate sensitive elements like environment variables, secrets, logs, configuration files, and access controls. Isolation prevents one tenant’s misconfiguration or failure from impacting others, and helps maintain compliance and data boundaries.
Shared Infrastructure
In a multi-tenant CI/CD system, many core components are shared across tenants to maximize efficiency and reduce operational overhead. These shared components typically include majority components discussed in this design:
- Build agents/executor: The machines or containers that execute build, test, and deployment tasks.
- Artifact Register: Centralized repositories that store build outputs and metadata such as binaries, container images, or static assets.
- Job queues and schedulers: Systems that orchestrate the execution order of jobs across all tenants.
- Databases: Shared metadata stores for pipeline states, logs, run histories, and job definitions.
The challenge is to ensure that despite sharing infrastructure, tenants remain logically isolated, so their pipelines, secrets, and performance do not interfere with one another.
Isolation Components
Isolation is a critical requirement in multi-tenant CI/CD systems to ensure security, reliability, and tenant independence. Here's a breakdown of what isolation must guarantee:
- Each tenant must have securely scoped secrets and environment variables
- Pipelines should run in isolated sandboxes or containers to prevent execution interference or file system collisions.
- Build artifacts and pipeline state must be stored separately—either logically or physically—with tenant-specific keys or namespaces.
- Logs, dashboards, and telemetry should also be tenant-scoped, ensuring visibility only into a tenant’s own data.
- The system must provide fault isolation, so a failure in one tenant’s pipeline doesn’t impact others—enforcing limits on compute, memory, and runtime to prevent noisy neighbor issues.
As you might have identified, sandboxes and containers are essential for isolation in multi-tenant CI/CD systems because they provide each pipeline with a clean, self-contained runtime environment. By isolating the file system, processes, and network space, they prevent one job from interfering with another—avoiding issues like file collisions, dependency conflicts, or unintended access to other tenants' data. This ensures that builds are secure, repeatable, and reliable, even when multiple jobs run in parallel on the same host. Once a job completes, its environment is destroyed, eliminating leftover state and further reinforcing tenant boundaries.
Deep Dive 4 - How do CI/CD systems manage safe parallel execution by ensuring concurrency control, avoiding race conditions, and maintaining idempotency?
Design a CI/CD system that supports parallelism at scale while ensuring:
- Concurrency control — avoid job interference and shared resource conflicts
- Race condition prevention — enforce safe sequencing where necessary
- Idempotency — ensure re-executed jobs produce consistent results
Parallel Execution via Isolated Job Runners
CI/CD systems execute builds and tests in isolated environments:
- Docker containers, ephemeral VMs, Firecracker microVMs, or Bazel sandboxes
- Each job has a clean filesystem, deterministic environment, and no access to shared global state
Concurrency Control via Dependency Graphs + Explicit Locking
Modern pipelines aren’t flat — they’re DAGs (Directed Acyclic Graphs). Each job or stage should:
- Declare dependencies explicitly
- Wait for upstream jobs to complete before starting
- Be scheduled based on its position in the graph
Please reference Deep Dive 2 to learn more about how correctness in build execution. For non-idempotent actions (e.g. terraform apply, k8s rollout, DB migrations), use:
- Distributed locks (like Redis, ZooKeeper, or a database row) make sure that only one job at a time can perform critical tasks, such as updating infrastructure. This prevents two jobs from changing the same thing at once and causing problems.
- Exclusive job gates (like
concurrencygroups in GitHub Actions) let you define a group of jobs where only one is allowed to run at a time. This keeps jobs from overlapping when they could interfere with each other, like two deployments to the same environment.
Race Condition Prevention via Merge Controls & Rollout Policies
CI/CD pipelines must coordinate concurrent source changes:
- Use merge queues / trains: Accept multiple PRs into a queue, build them one-by-one, merge only after tests pass.
- Use immutable artifact promotion: Artifact X should not change once promoted to staging or prod.
- Use canary/blue-green rollouts to gate high-risk deploys.
Idempotency via Immutable, Versioned Artifacts
Idempotency means: Running the same job twice should produce the same result.
Achieve this by:
- Using content-addressed storage (e.g., SHA256 of input tree) for builds
- Making deployments reference immutable artifact versions (e.g., Docker tag = commit SHA)
- Avoiding side-effects in steps unless guarded by checks (e.g., “create if not exists”)
Design principle: Treat builds and deploys like pure functions — same input = same output.
Remote Caching & Safe Reuse of Work
Leverage remote build caches to avoid redundant work:
- Share results across developers and CI agents
- Protect cache integrity with content hashes
- Namespace caches to avoid clashes (e.g., per-branch or per-job-key)
Design principle: Reuse is safe only when correctness is guaranteed.
Final Thoughts
Designing a CI/CD platform isn’t just wiring up a few YAML files — it’s building a reliable, multi‑tenant, event‑driven factory that turns code into safely deployable artifacts at scale. The goal is fast feedback for developers, correctness you can trust, and operations that don’t wake up on‑call.
In this guide, we walked through the core building blocks — priority‑aware scheduling and queues, isolated runners, immutable artifacts with rich metadata, progressive delivery, and automatic rollback. More importantly, we explored the tradeoffs that senior engineers must navigate in real systems:
- Concurrency & Queuing at Scale
Smart schedulers, backpressure, and debouncing keep 500+ concurrent builds moving while reserving lanes for hotfixes and release trains. - Correctness & Reproducibility
Immutable, versioned artifacts plus DAG‑driven builds (e.g., Bazel) ensure the right things build in the right order, are cacheable, and are bit‑reproducible across machines. - Safe Delivery & Instant Rollbacks
Progressive rollouts (blue/green, canary) gate risk; metadata‑driven promotion and artifact pinning make rollbacks a 30‑second redeploy—not a panic rebuild. - Multi‑Tenant Isolation & Fairness
Containers/microVMs, scoped secrets, resource limits, and concurrency guards prevent noisy neighbors, enforce fair share, and keep tenants securely separated.
Put together, these pieces form a resilient CI/CD backbone: fast where it should be, strict where it must be, and transparent end‑to‑end with dashboards, alerts, and audit trails.