
Functional Requirements
1. Users can send and receive messages in 1:1 or group chats
This covers both private and group conversations, with messages delivered in order and stored persistently. Group chats can support dynamic membership and maintain message history.
2. Users can send rich media (e.g., images, videos, files) as part of a message
Messages can include text, attachments, or both. The system must support media upload, storage, and preview rendering across devices.
3. Users can receive real-time notifications for new messages
When a user receives a new message—either in a direct chat or group—they should be notified through in-app indicators, push notifications, or email (based on settings and availability).
4. Users can delete their own messages from a chat
A user should be able to remove a message they previously sent. The deletion may be visible (e.g., “This message was deleted”) or fully removed from view, depending on the UX and policy.
Non-Functional Requirements
1. High Scalability
The system should support 1 B users and 100k chats concurrently, especially in high-traffic group chats.
Illustration: Imagine a global company’s #all-hands channel with 100k active users — your system must fan out messages quickly without bottlenecks.
2. Low Latency in Chat Delivery
Aim for P95 end-to-end message latency under 200ms for online users.
Illustration: A user sends a message and expects to see it reflected across all devices in near real-time — delays over 500ms degrade the user experience.
3. CAP - Aware Messaging Guarantees
The system should prefer high availability, but must enforce strong ordering consistency within each chat room.
Illustration: Even if one server fails, the user should still be able to chat — and messages in a group must never arrive out of order.
4. Message Durability
Messages must be safely persisted before confirming to the sender. No acknowledged message should be lost, even if the server crashes right after.
Illustration: If a user hits send and then immediately loses internet, the message must still exist when they reconnect.
5. Consistent in Multi-Device
Users often stay logged in on multiple devices — desktop, phone, tablet — at the same time. The system must ensure that messages, read receipts, and typing indicators remain synchronized across all active sessions. Events such as message delivery, deletion, or read status must be reflected in real-time across all clients.
Illustration: A user reads a message on their laptop — seconds later, their phone reflects it as read, clears the notification badge, and doesn’t re-alert them. We put this in the end, is to make sure all above functions can be fulfilled first and cross-device session can hold them all.
Requirement Summary
Before diving into Entities & APIs, you may notice that we’ve spent a significant amount of time unpacking both functional and non-functional requirements. That’s intentional. In many existing materials, this critical phase is often rushed or oversimplified — but in real-world design and high-level interviews, clarity around what the system must do and how it must behave under pressure is what separates great solutions from generic ones. We aim to set a higher bar here, not just to define the problem well, but to invite thoughtful trade-off discussions, scalability considerations, and system behaviors that hold up in production. The better your foundation, the sharper your design decisions will be — and we’ll carry that mindset through the rest of this article.
Core Entities
APIs
In traditional REST APIs, clients make requests and receive responses. But Slack-like chat apps require bi-directional, low-latency communication, which is best achieved with WebSocket.
Once connected, the server and client exchange structured events, such as new messages, read receipts, typing indicators, etc. There’s no need to repeatedly poll. Here is all supported WebSocket events:
High Level Design
FR1 - User can send and receive messages in 1:1 or group chats
Let’s illustrate from step to step.
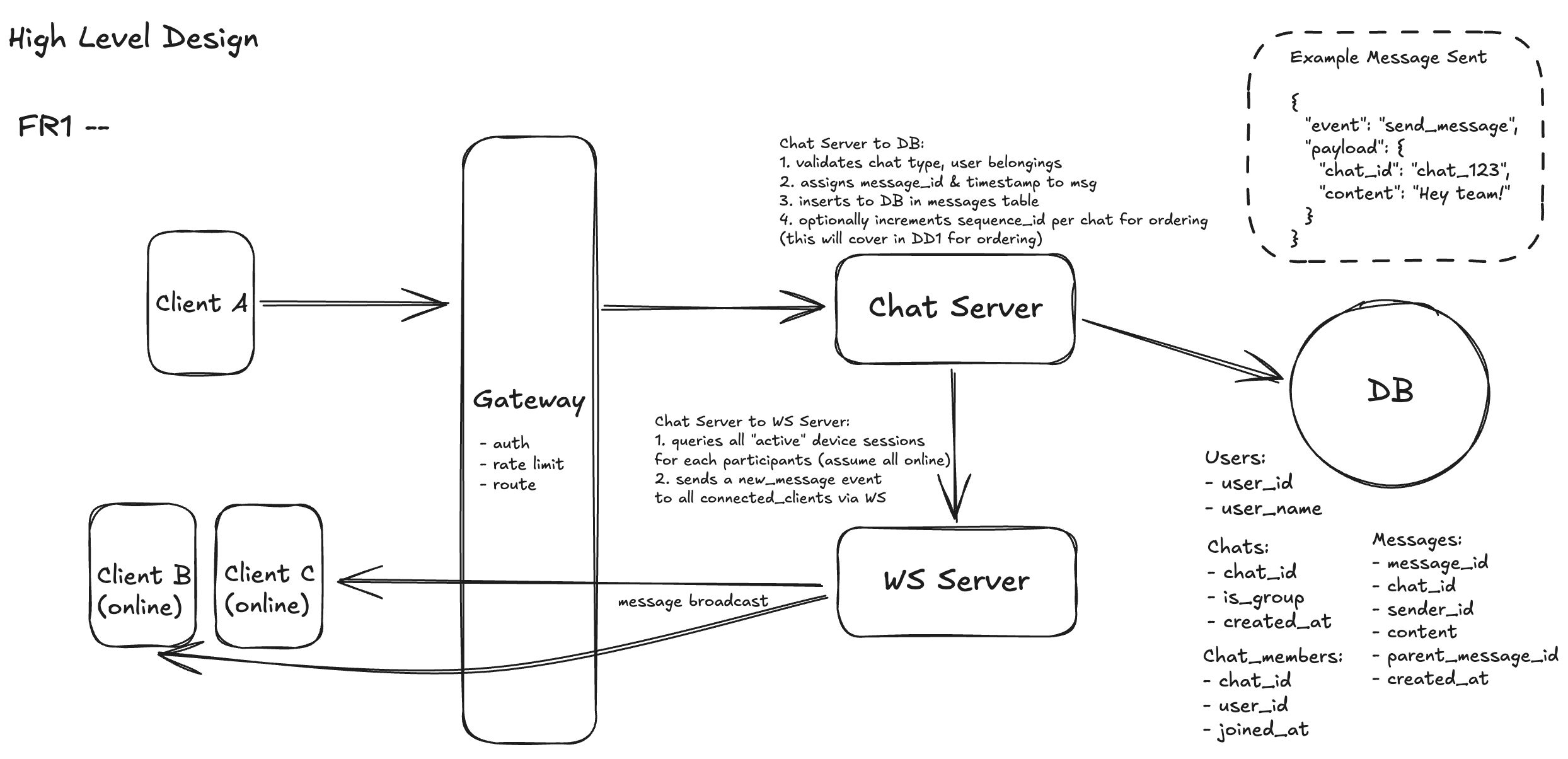
1.User Sends Message from Client
When a user sends a message in a Slack-like chat system, the action begins on the client side. The user types a message in either a 1:1 or group chat and hits “Send.” The client emits a send_message event over an established WebSocket connection, including the chat_id, message content, and optionally a parent_message_id if the message is a threaded reply.
2.Gateway Handles Authentication and Routing
This event is first handled by the Gateway, which acts as the system’s front door. The Gateway authenticates the user session, checks rate limits, and determines routing based on the target chat. Once validated, the event is forwarded to the appropriate Chat Server instance — typically determined by a consistent hashing or partitioning scheme that ensures messages for the same chat are handled in order.
3.Chat Server Validates Membership and Writes to DB
The Chat Server receives the request and performs core validation logic. It checks that the specified chat_id exists in the chats table and confirms that the sender is indeed a member of the chat by querying the chat_members table. This step guarantees that only authorized participants can write to the chat.
Once validated, the server generates a message_id and a timestamp. It writes a new record into the messages table using a straightforward schema: message_id, chat_id, sender_id, content, and created_at. If the message is part of a thread, the optional parent_message_id is also populated. This design allows for both flat and threaded message retrieval without needing a separate thread table.
4.Message is Broadcast to Participants via WebSocket
After persisting the message, the Chat Server initiates real-time delivery. It queries all current participants of the chat via chat_members, then looks up each participant’s active WebSocket connections (offline users we will cover in FR3). A new_message event is emitted to every connected device, allowing clients to instantly receive and render the new message in their chat window.
Because this flow uses WebSocket for delivery, online users experience near-instant feedback. The message arrives without polling or refresh, and appears with accurate sender, timestamp, and optional thread context. This seamless propagation is what gives Slack and similar apps their fluid, real-time feel.
FR2 - User can send rich media (e.g., images, videos, files) as part of a message
To support rich media, we extend the message-sending flow to decouple media upload from message delivery. Files are stored in an object store like S3, and the message contains only a reference (media ID or signed URL). This keeps our messaging system lightweight and responsive.
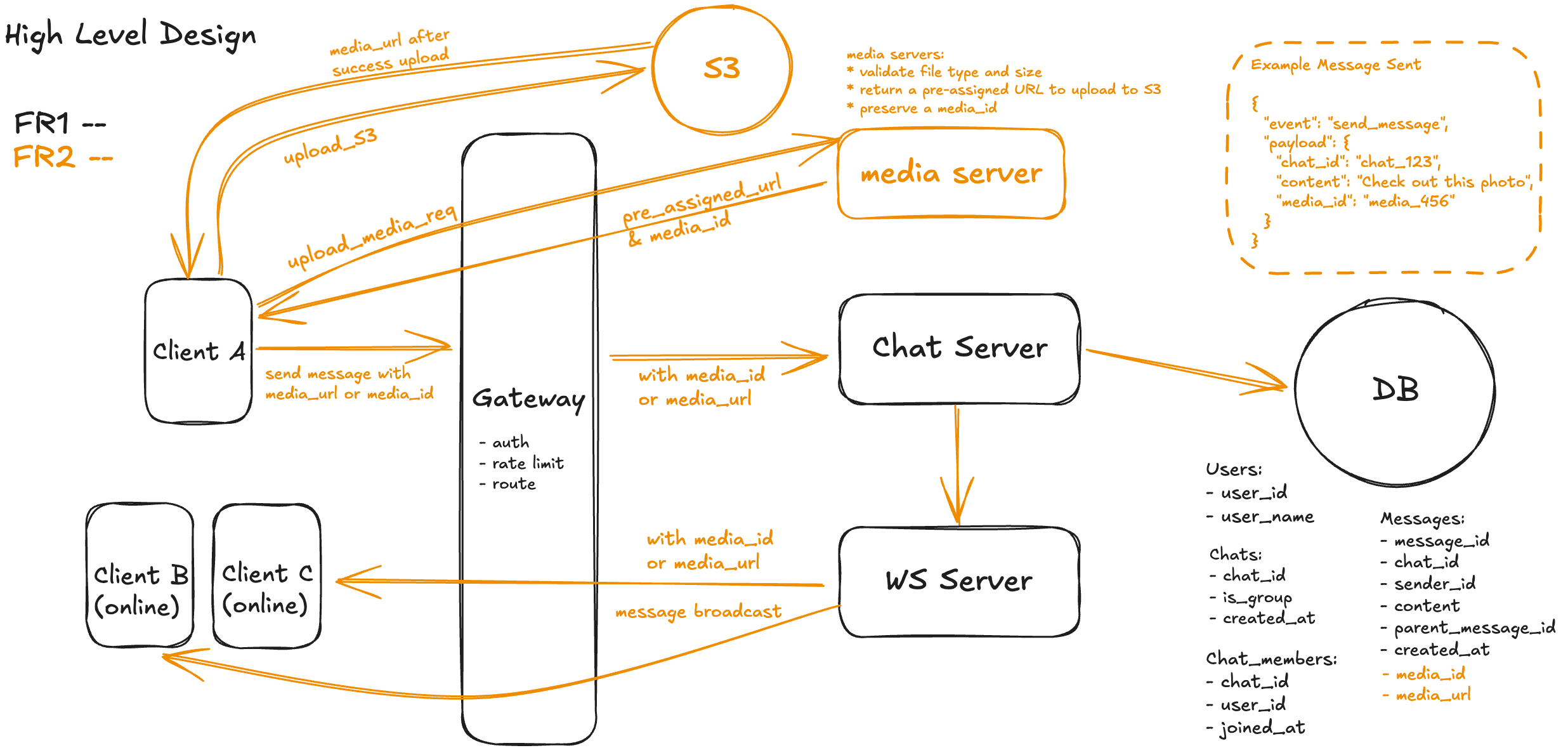
1. Client Requests Upload URL
When the user selects a media file, the client sends a /upload_media_req call to the media server. The media server checks the user’s auth, validates file type and size (optional), and returns a pre-signed URL for direct upload to S3. It may also reserve a media_id to track the object.
2. Client Uploads File to S3
The client then uploads the file directly to S3 using the pre-signed URL. This avoids proxying the file through backend servers and offloads transfer to the object store. Upon success, the media server returns the final media_url (or the client constructs it from the media_id), which will be embedded in the outgoing message.
3. Client Sends Message with Media Reference
Once the upload completes successfully, the chat UI enables the “Send” button. The client emits a send_message event over WebSocket with the message content and the media_id or signed media_url. No binary data is transmitted through this path.
4. Gateway and Chat Server Handle Message
The Gateway forwards the message to the Chat Server. The Chat Server validates chat membership and that the media reference is owned by the sender. It then inserts the message (including media_id or media_url) into the messages table, and proceeds to fan it out like a regular message.
5. Clients Receive and Render Media
The WebSocket Server delivers a new_message event to all online recipients, which now includes the media_url. Clients render previews (thumbnails, play buttons, etc.) using the signed URL — valid only for a short time (e.g., 1 hour) to preserve security and access control.
FR3 - User can receive real-time notifications for new messages
Real-time messaging isn’t just about sending and receiving messages while the app is open. Users must be notified of new activity, even when they’re offline, the app is in the background, or they’re using another device. A scalable Slack-like system must support both WebSocket push for online users and push notifications for offline users — all while respecting user preferences and minimizing redundant alerts.
In this way, we need to come up a diagram (blue part in the diagram below) with 2 phases:
- one with client offline, the system identify is offline state, persist rows into inbox table and send notification via APNs. (use solid lines for online state)
- the other one with client back to online via notification click, how the message is actually delivered and inbox cleanup based on retention. (use dash lines for offline state)
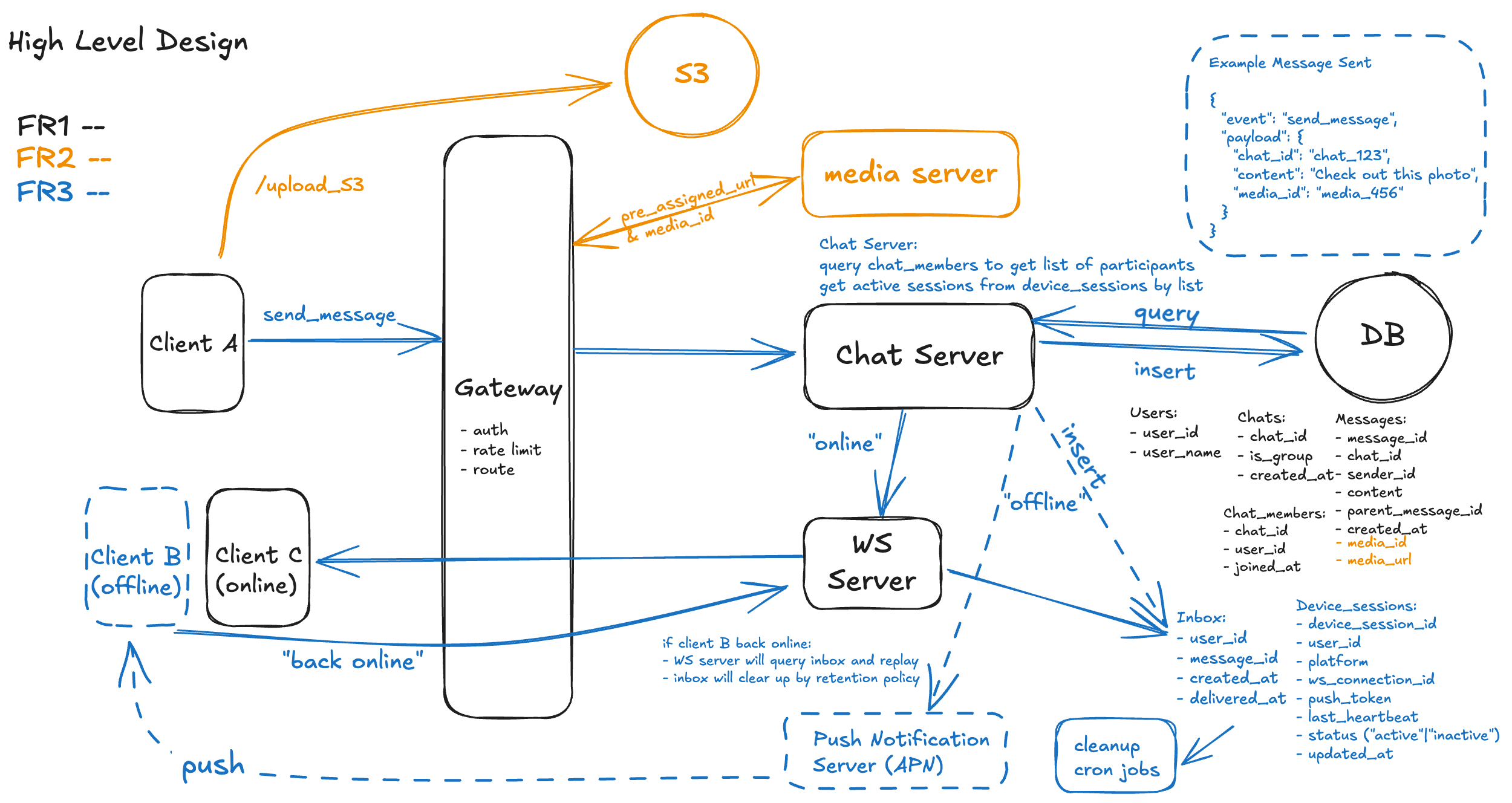
Here is the illustration of detailed steps based on the diagram:
1. Client Sends a Message via WebSocket (Same as previous)
The process starts when the sender (Client A) emits a send_message WebSocket event. This event includes fields like chat_id, content, and optionally media_id. It is routed through the Gateway for authentication and rate-limiting.
2. Gateway Authenticates and Routes the Event (Same as previous)
The Gateway validates the user’s identity, enforces rate limits, and forwards the request to the appropriate Chat Server based on routing logic like consistent hashing of the chat_id.
3. Chat Server Validates Chat Membership (Same as previous)
The Chat Server queries the chat_members table to confirm the sender belongs to the chat. It then fetches the list of all chat participants.
4. Chat Server Determines Online vs. Offline Users
Using the list of participants, the Chat Server queries the device_sessions table to identify which users are currently online. A session is considered active if the status is "active" and last_heartbeat is within an acceptable threshold.
5. Message is Persisted in the Database (Same as previous)
A new record is inserted into the messages table with metadata such as message_id, chat_id, sender_id, content, and optional media_id. This ensures durable storage before any delivery.
6. Insert into Inbox for Offline Users
For every offline participant, a record is created in the inbox table. Each entry contains user_id, message_id, created_at, and an optional delivered_at timestamp once delivered.
7. Real-Time Fanout via WebSocket Server for Online Users
The Chat Server pushes the message to the WebSocket Server, which fans out a new_message event to all connected clients based on their ws_connection_id in device_sessions.
8. Push Notification for Offline Devices
If an offline user has a registered push_token, the Chat Server triggers a notification through the Push Notification Server (e.g., FCM, APNs). This is only a notification and does not mark the message as delivered.
9. Message Replay on Reconnect
When an offline user comes back online (e.g., reopens the app), the Gateway re-establishes the WebSocket connection. The WebSocket Server queries the inbox table and sends all undelivered messages to the client. Delivered messages are then marked with delivered_at.
10. Cleanup via Retention Policies
A background cron job routinely scans the inbox table to delete old undelivered messages (e.g., after 30 days) based on the system’s data retention policy. This ensures storage efficiency and limits stale state buildup.
FR4 - User can delete their own messages from a chat
Now, let’s come to answer one of the challenging questions we asked in the beginning of the article - “how to support message deletion”.
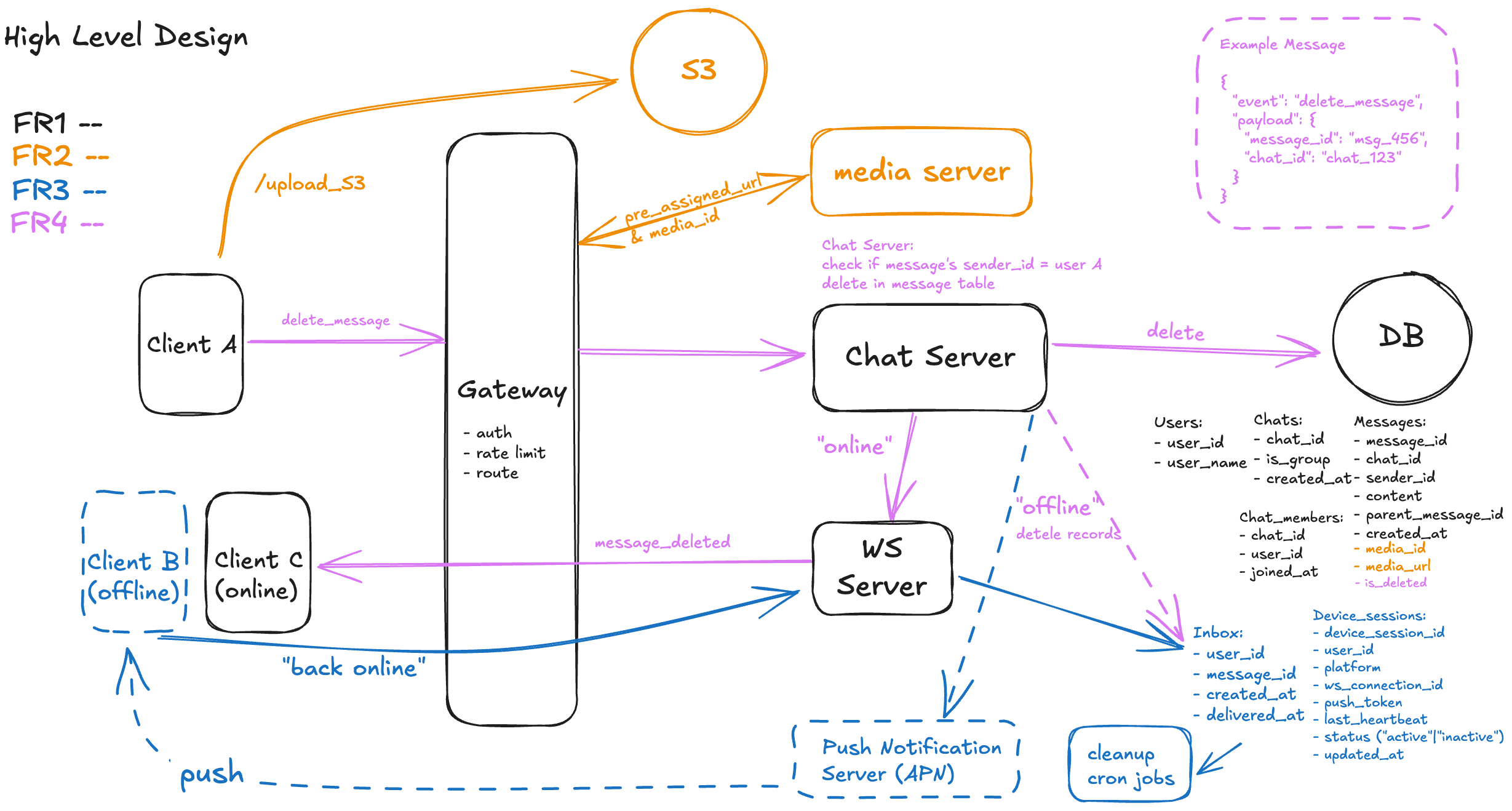
1. Client Sends delete_message Request
The deletion process begins when the sender (Client A) initiates a message deletion from the chat UI. The client emits a delete_message WebSocket event containing the message_id and chat_id in the payload. This request is routed through the Gateway, just like send_message, and forwarded to the appropriate Chat Server instance.
2. Gateway Authenticates and Routes the Deletion
The Gateway performs standard checks — user authentication, rate limiting, and routing — then forwards the delete_message request to the corresponding Chat Server. It does not modify the payload or perform authorization beyond the identity of the sender.
3. Chat Server Authorizes and Soft Deletes Message
Upon receiving the request, the Chat Server first validates that the message exists and that the requesting user is indeed the original sender. It queries the messages table by message_id and checks that sender_id == user_id. If the check passes, the Chat Server updates the message row to mark it as deleted. This is implemented as a soft delete by adding a new boolean column is_deleted (default: false) to the messages table and setting it to true.
4. Chat Server Fan-Outs Deletion to Online Participants
Next, the Chat Server queries the chat_members table to identify all participants of the chat. It then cross-references the device_sessions table to determine which participants are currently online. For those with active WebSocket connections, a message_deleted event is immediately emitted from the WS Server, instructing the clients to remove the message with that message_id from their view.
5. WS Server Generates Inbox Records for Offline Users
For chat members who are offline (i.e., without active WebSocket sessions), the WebSocket Server inserts an entry into the inbox table for each message that needs to be delivered later. Each row contains the user_id, message_id, delivered = false, inserted_at, and to_be_deleted = false.
If the sender deletes a message while some recipients are still offline, the system checks whether it had already been delivered to each user. If the message was never delivered (i.e., delivered = false), the corresponding inbox row is either deleted or skipped — no message_deleted event is sent to the client. The recipient will never know that message existed.
Only messages that were previously delivered will emit a message_deleted event when deleted, ensuring the interface is updated accordingly. This approach keeps the system clean and intuitive for the recipient, and reduces unnecessary deletion traffic for messages they never saw.
6. Deleted Message is Omitted from Scrollback Queries (Online Users only)
The deletion is visually enforced by excluding messages with is_deleted = true in any message list query. When offline clients come back online and load the chat history, the deleted message will be filtered out entirely, appearing as if it never existed.
Data Schema Summary
After walking through the high-level design and functional workflows, it's crucial to ground our system with a clear view of the data model. The tables presented below summarize the persistent entities that power our Slack-like chat system — from messages and media to session tracking and inbox management. This snapshot not only helps engineers understand what gets stored and queried behind each API or flow, but also serves as a bridge to implementation. Defining schema early also surfaces key tradeoffs around indexing, normalization, and consistency boundaries — especially at scale.
Deep Dives
While the current design covers the end-to-end messaging, media handling, notifications, and deletion workflows, two complex areas remain unresolved and require deeper architectural consideration. First, ensuring strict message ordering and multi-device consistency becomes challenging when users operate from multiple clients — race conditions, duplicate receipts, and out-of-order views can easily arise without proper state coordination. Second, the system must scale to millions of users while maintaining real-time responsiveness, which puts pressure on the WebSocket infrastructure and active session lookup mechanism — especially when determining online/offline status at scale or routing fan-out efficiently. To address these bottlenecks and fulfill our original challenges, we’ll dedicate three deep dives to:
- Message Ordering in Group Chat at scale
- Scalability of WebSocket Infrastructure & Active Session Lookup
- Multi-Device Consistency
DD1 - Message Ordering Consistency
To solve this problem and improve the performance of our current design, there are 3 options to discuss.
Option 1: Client-Side Timestamps
In this approach, the client attaches a timestamp when sending a message, and the server simply stores and uses that for ordering. While this may seem straightforward, it introduces significant risk in distributed multi-device scenarios: user devices often have unsynchronized clocks, leading to inconsistent ordering across clients. Worse, malicious or buggy clients could manipulate timestamps to reorder the conversation. This option is too fragile to support strong consistency expectations in real-time chat.
Option 2: Server-Side Sequence Number per Chat
Here, the Chat Server maintains an atomic, per-chat counter (e.g., chat_456 → seq=502) that increments with each new message. Each message is assigned a unique, monotonically increasing sequence_number during ingestion and persisted in the messages table. All queries, rendering, and read receipts use this sequence for deterministic order. This guarantees correct ordering even with concurrent multi-device sends. The downside is that atomic increments can become a bottleneck at high scale unless each chat is strictly routed to a single partition or server shard. Still, for many medium-scale systems, this option balances correctness with implementation simplicity.
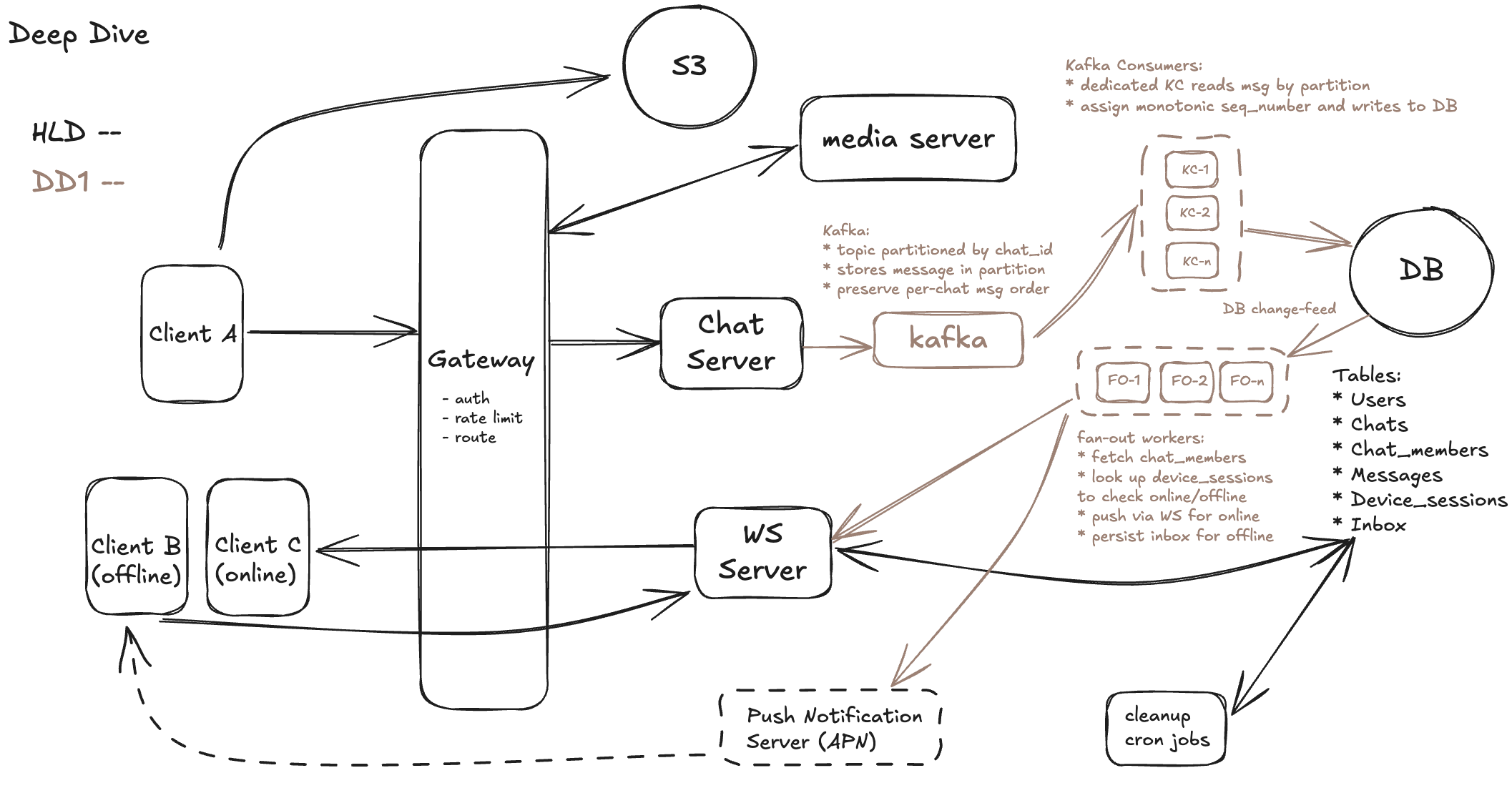
Option 3: Kafka-Based Ordered Ingestion per Chat (Recommended)
This design routes all incoming messages through Kafka, mapping each chat to a specific Kafka partition using a consistent hash of chat_id. Kafka natively enforces strict message order per partition, so concurrent sends across devices are correctly serialized. A consumer service reads from each partition, assigns a sequence_number, and writes messages into the database in order. This architecture scales horizontally — as chats grow, more partitions can be added. It also enables async processing like analytics or moderation. The trade-off is increased infrastructure complexity (Kafka ops, offset management, retry logic). But for high-scale systems like Slack, this model decouples ingestion from persistence while providing strong ordering guarantees out-of-the-box.
Based on the previous discussion, our diagram improved as follow:
DD2 - Scalability of WebSocket Infrastructure & Active Session Lookup
Scalability Bottleneck 1: Active Session Populate
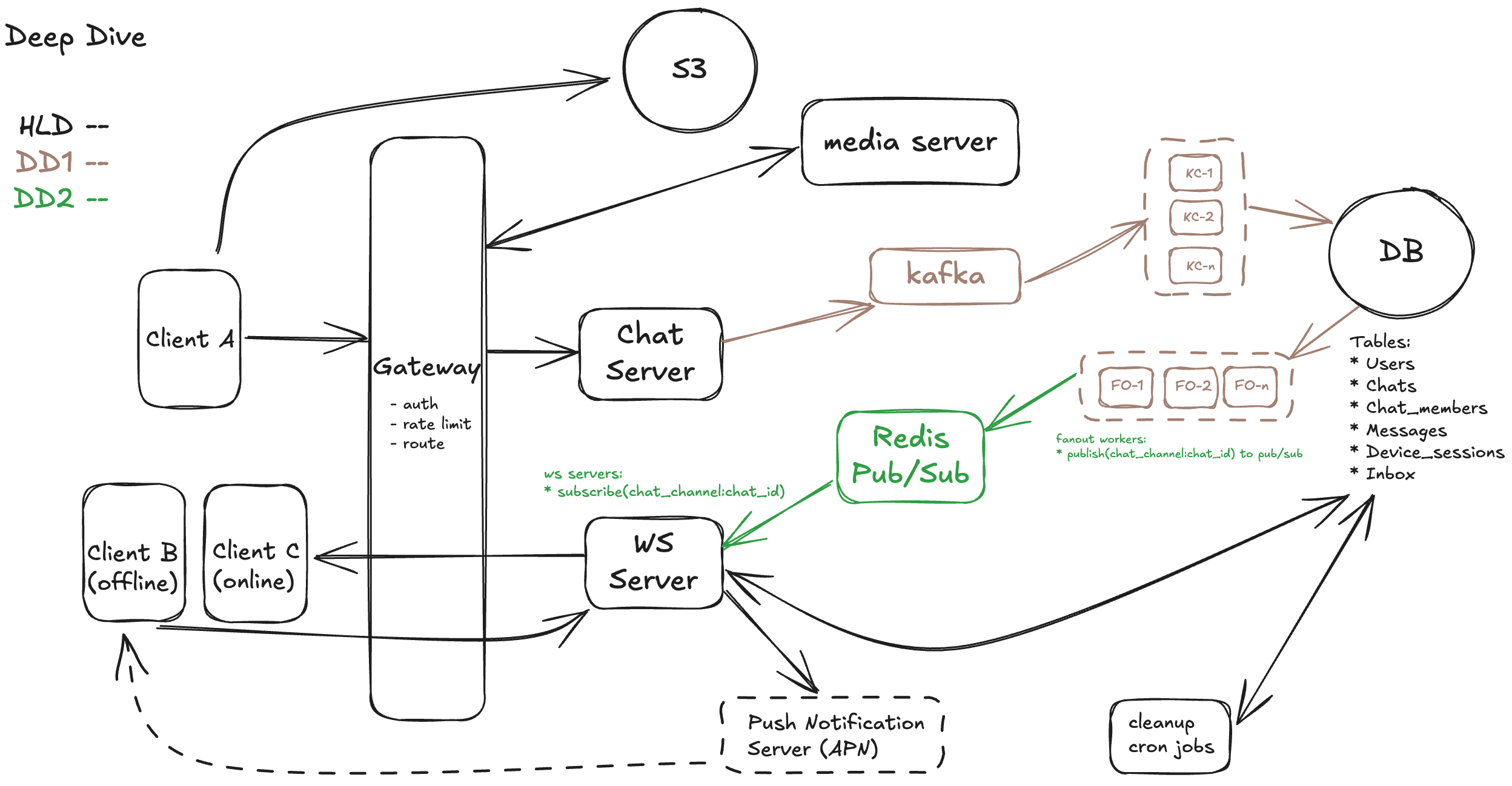
At 100M+ concurrent users, the challenge isn’t just about querying where each user is — it’s about how WebSocket servers can efficiently populate and manage active session data in real time, without overloading Redis or requiring centralized lookup for every message.
To avoid this, we recommend shifting to a Pub/Sub fanout model, which scales much more effectively. We can publish all messages to chat-specific channels in a distributed Pub/Sub system (e.g., Redis Streams, Kafka, or NATS). Each WebSocket server dynamically subscribes to the chat channels for the rooms its connected users participate in.
Here is the updated design diagram with data flow illustration:
Scalability Bottleneck 2: WebSocket Server Churn (Users Moving Between Nodes)
Even with recommended solution above, in our current design (Deep Dive 2), each WebSocket server dynamically subscribes to Redis Pub/Sub channels like: chat_channel:<chat_id>. Based on the chat rooms its connected users participate in. But if a user churns (e.g., disconnects and reconnects quickly on a different server), you get some issues:
- Stale subscriptions: the old WS server is still subscribed to channels for a user it no longer owns.
- Missed/unnecessary fanout: Redis may still push messages to the old WS server, wasting network and compute.
- Racing conditions: during rapid reconnects, both the old and new servers may subscribe at the same time.
So the goal here is to ensure only one WebSocket server is subscribed to a given user's chat channels — the one currently serving that user — and update this dynamically as users move.
Here are potentially 2 options to think about:
Option 1: Always Subscribe to All Chat Channels on Connection
In this approach, when a user connects to a WebSocket server, that server looks up all the chats the user is part of (via chat_members table) and immediately subscribes to all corresponding Redis Pub/Sub channels (e.g., chat_channel:<chat_id>). This ensures that the server receives all relevant messages during the user's session. However, if the user reconnects and is routed to a different WebSocket server, both servers may now be subscribed to the same chat channels, potentially duplicating effort. There's no coordination to ensure only one server is actively managing the delivery. This makes the system simpler to implement but leads to wasteful fanout, unnecessary memory pressure, and risk of duplicate messages unless clients de-dupe.
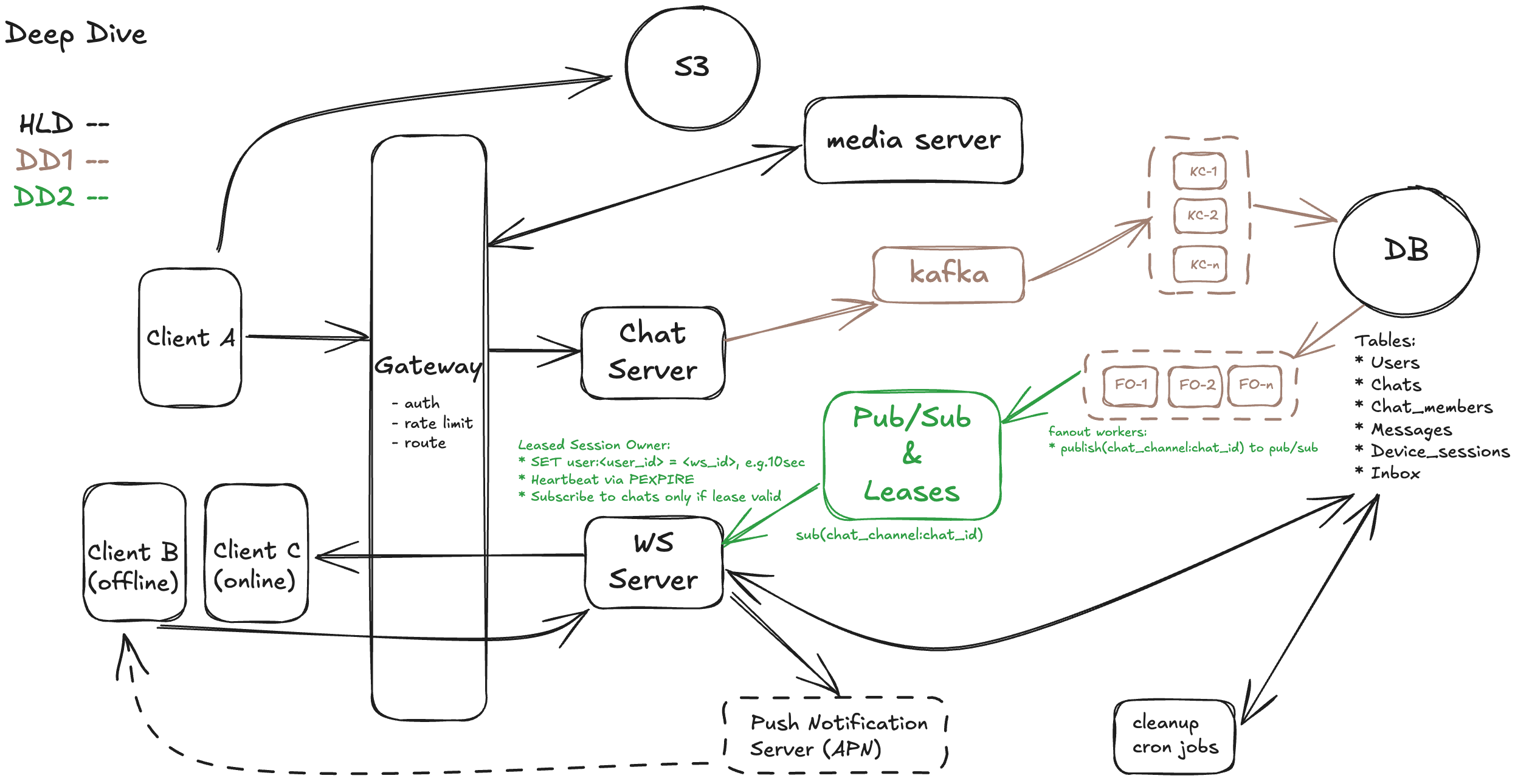
Option 2: Leased Session Ownership with Redis TTL (Recommended)
This approach uses Redis to coordinate which WebSocket server owns a user's session at any given time. When a user connects, the WS server sets a key like user:<user_id> = <ws_id> with a short TTL (e.g., 10 seconds) and extends it periodically with a heartbeat (PEXPIRE). Only if a server holds the valid lease does it subscribe to the user’s chat_channel:<chat_id> channels. This guarantees that only one WS server is responsible for delivery per user, avoiding duplicates and reducing fanout overhead. However, it requires more infrastructure coordination, handling edge cases like lease expiration or reconnect races, but pays off in cleaner scalability and efficiency at very large user scale.
Based on Option 2 as we recommend, here is the updated diagram:
Scalability Bottleneck 3: Backend Storage Pressure (DB Write & Read Load)
At the scale of billions of users and hundreds of millions of concurrent sessions, your backend storage becomes a critical bottleneck — particularly around fanout writes, message reads, and metadata lookups during WebSocket reconnects or chat bootstrapping.
There are several strategies we could apply, during your interviews, if you can answer with the 2 main points, that should be well enough.
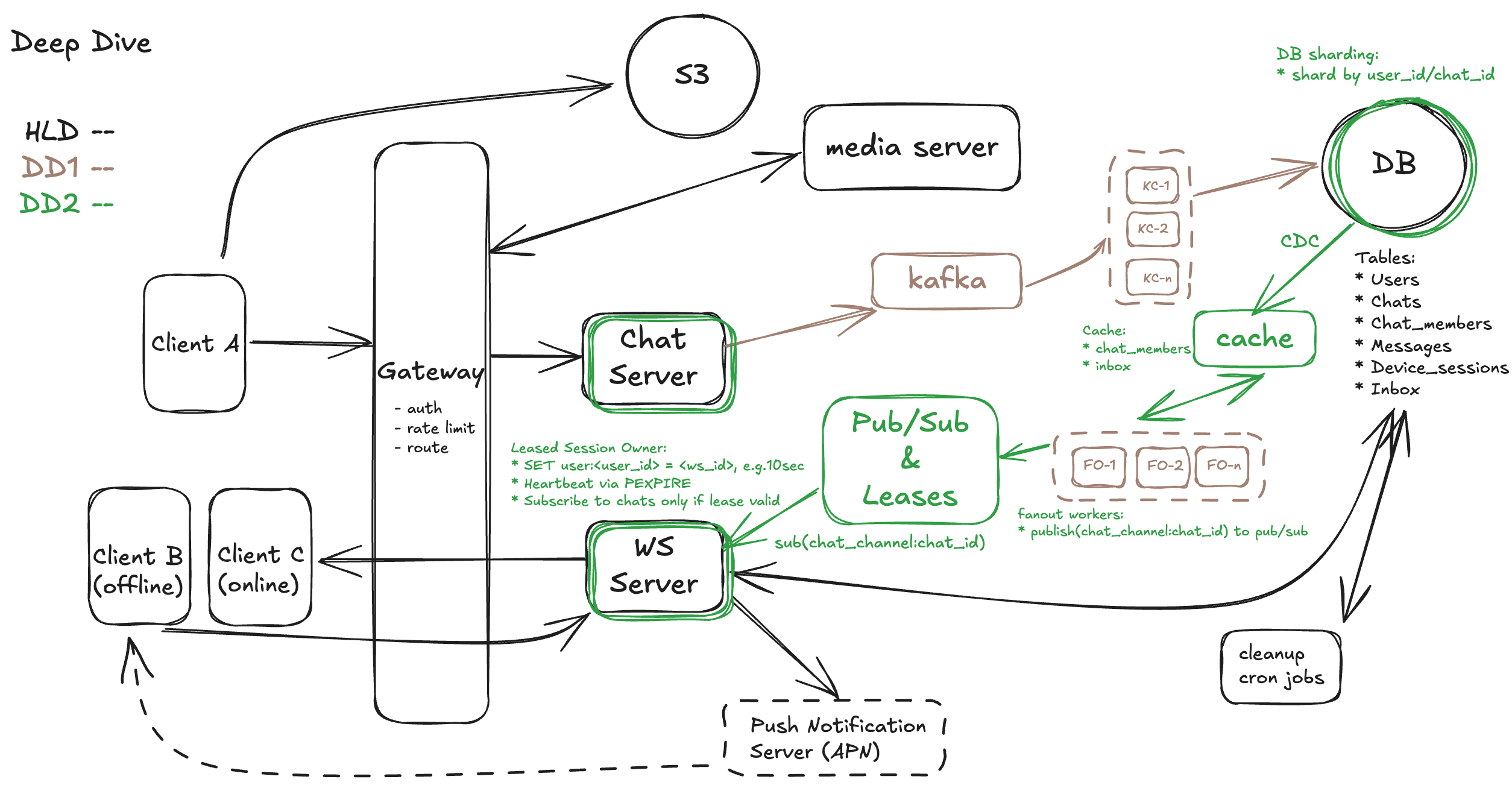
Strategy 1: Horizontal Partitioning of Messages & Inbox Tables
To handle the massive write load — especially for group messages that fan out to many recipients — we recommend horizontally partitioning the messages and inbox tables. This can be done by sharding based on chat_id (for messages) and recipient_user_id (for inbox). This distributes the write and query load across multiple physical nodes or database instances. A NoSQL system (like DynamoDB with composite keys) can be used, depending on your durability and consistency requirements. The key tradeoff is managing cross-shard queries (e.g., listing a user’s recent chats), which must be handled carefully via query fanout or index denormalization.
Strategy 2: Read-Optimized Caching for Hot Metadata & Fanout Paths
For high-throughput lookups (e.g., chat_members, device_sessions, user presence), introducing dedicated caching layers like Redis or Memcached can significantly offload the primary database. For example:
- Cache active chat membership per user (
user:<id>:chats) - Cache online device sessions (
user:<id>:devices) - Cache recent message slices (
chat:<id>:recent_messages)
These caches should be asynchronously updated via change data capture (CDC) streams or near-real-time workers. They reduce DB read QPS during WebSocket reconnection, chat scrollback, or large fanouts. However, challenges include cache invalidation on membership changes and consistency under race conditions, so TTLs and refresh policies must be carefully tuned.
Hence, with all the recommended improvement, the design diagram looks like this:
DD3 - Multi-Device Management
Proposed Solution: Per-Device Session Registry + Inbox Replay
To support seamless multi-device experience, we break the problem into online and offline flows, and handle them with a mix of local mapping and durable persistence.
Step-by-Step Message Delivery Flow (Multi-Device Aware)
1. Device Connects
- When a user device connects to the WebSocket server, it registers its session by writing:
device_sessions:{user_id}:{device_id} → ws_connection- (typically stored in Redis or an in-memory map).
2. Message Fanout
- When a new message is delivered (via Pub/Sub fanout), the WebSocket server looks up all active sessions for the recipient user.
- It sends the message to each connected device (e.g., both phone and desktop).
3. Offline Fallback
- If a device isn’t connected, the message is stored in the inbox table, keyed by
user_idanddevice_id. - This ensures the message is queued for delivery when that device comes back online.
4. Device Reconnects
- Upon reconnection, the server checks the inbox for that specific
(user_id, device_id)and delivers any missed messages. - After successful delivery, the entries are cleared or marked as delivered.
Final Thoughts
Designing a Slack-like system goes far beyond just sending and storing messages. It’s about architecting a real-time, distributed, resilient messaging backbone that can support massive concurrency and device diversity — all while keeping latency low and user experience seamless.
In this article, we walked through every major building block — from creating chats, managing group members, to sending rich media, storing messages, and triggering WebSocket or push notifications. More importantly, we explored deep-dive design tradeoffs that help you answer four of the toughest system design challenges often brought up in interviews:
- Message Ordering in Group Chat: We use Kafka-based ingestion and per-chat sequence numbers to enforce a canonical timeline for all messages — ensuring consistent rendering even when messages are sent concurrently from distributed devices.
- Real-Time Notifications at 100M+ Scale: We designed an online + offline fanout mechanism using WebSocket and inbox tables, and built in notification delivery through Redis pub/sub and fallback logic for offline users — without overloading the backend.
- Deletion Propagation with Retention Guarantees: We built an audit-compliant deletion flow that respects sender-side deletion, ensures correct client updates across devices, and prevents resurfacing of deleted content via inbox filtering or replay rules.
- WebSocket Churn and Multi-Device Reconnects at Scale: We tackled infrastructure churn by introducing session leasing with Redis TTL, a pub-sub based fanout by chat channel, and client-side deduplication to handle reconnect storms — ensuring clean handoff and minimal duplication when users rapidly connect from multiple locations.
Together, these answers formed the backbone of a resilient, scalable chat infrastructure. Each challenge covered with trade-offs between consistency, scalability, latency, and complexity — and our deep dives laid out concrete, production-ready solutions for each.