
Functional Requirements
- FR1: Scheduling (Immediate Execution) — The system must support running jobs immediately (run now).
- FR2: Scheduling (Future & Recurring Execution) — The system must support running jobs at a specific future time or on a recurring cadence (e.g., every Monday at 8:00 AM).
- FR3: Observability — The system must provide visibility into overall health, including queue depth, success/error rates, latency, and worker status.
Non-Functional Requirements
- High Scalability — The system should support up to 10,000 job executions per second.
- Low Latency — Jobs should be executed within 2 seconds of their scheduled time.
- Correctness — Ensure at-least-once execution, with delivery semantics configurable (e.g., at-most-once, exactly-once) based on use case.
- High Availability — The system must be highly available, favoring availability over strict consistency.
- Fault Tolerance — The system must tolerate worker crashes, network partitions, and partial failures, with mechanisms for automatic retries, failover, and recovery without data loss.
Core Entity
To tie these requirements together into a coherent architecture, we begin with two foundational building blocks: the Job and the Job Run.
Job — The Blueprint of Work
A Job is the reusable definition of what needs to be done. It defines:
- The action or task to perform (e.g., “send email”, “run backup”)
- Optional input parameters or configuration
- Its intended schedule (e.g., immediate, cron)
- Priority or policy metadata
A Job is not tied to a specific execution. Think of it as a template — it can be reused across different times, contexts, or users.
Job Run — A Specific Execution of That Job
A Job Run is a concrete instance of a job being executed. It defines:
- When the job is to be run (
available_atorscheduled_time) - The actual input payload or overrides
- Execution status (
queued,running,succeeded,failed) - Retry count, error codes, logs
If the Job is the blueprint, the Job Run is the actual build based on that blueprint.
For example:
- The Job is “generate sales report.”
- A Job Run would be “generate sales report for Q2 2025 at 6:00 AM Monday.”
High Level Design
FR1: Scheduler component to support immediate job execution
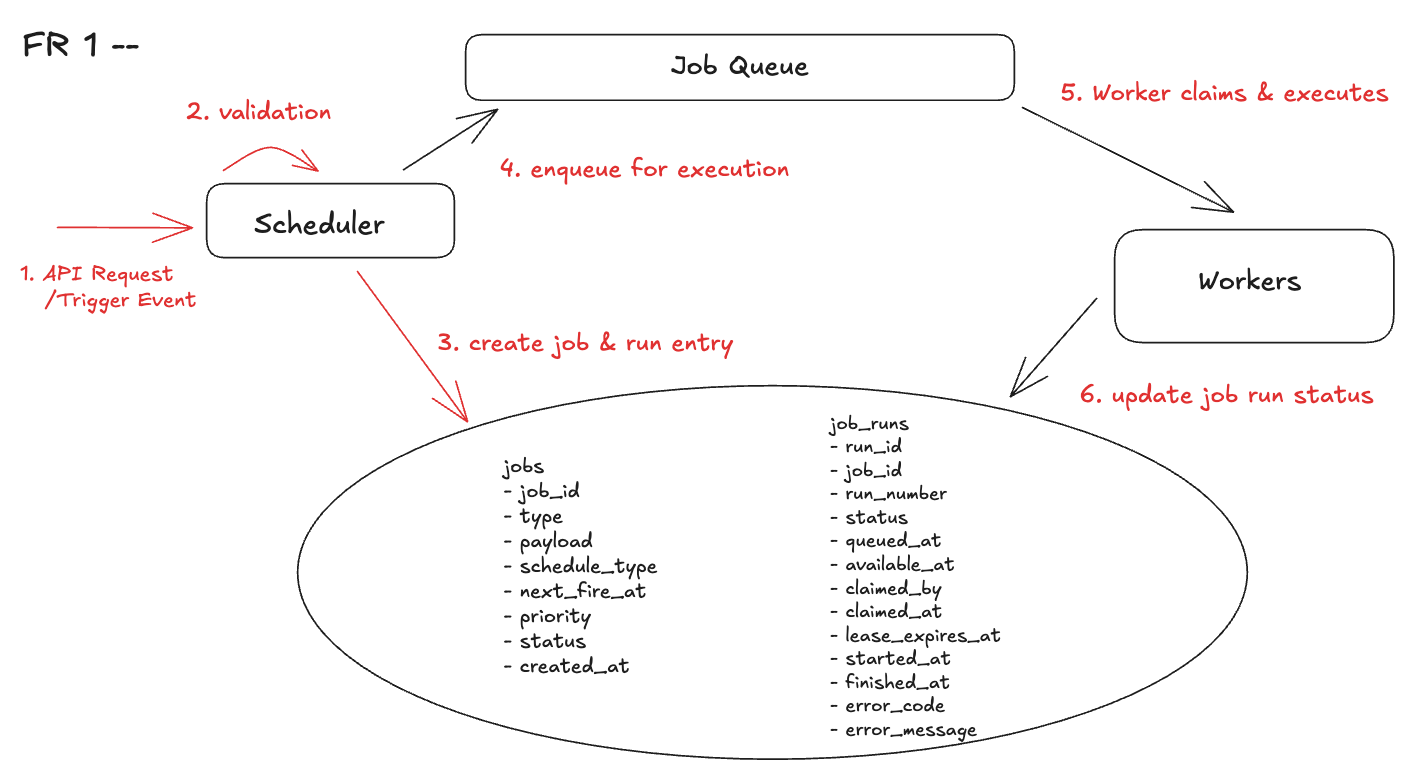
When designing a distributed job scheduler, it's easier to start by supporting immediate job execution —that is, jobs that should run as soon as they're created. This lays down the core scheduling loop without needing to deal with cron parsing or future timing calculations. By focusing on the now, we can build the foundation for more complex features like delayed and recurring jobs.
The essential flow for immediate jobs can be summarized as:
Record Intent → Enqueue → Lease → Execute → Record Outcome → Retry if Needed
Step-by-step data flow:
Step 1: Receive the Job Request
The client or upstream service issues a request to run a job immediately — no run_at , no cron , no future schedule. This defines the intent to execute. Nothing actually runs yet.
Step 2: Validate and Normalize
The scheduler authenticates the request and generates a unique job_id . It marks the job withschedule_type = immediate so that all downstream components know this is eligible to run rightaway.
Step 3: Atomically Write Job and Run
In a single transaction, the system:
- Inserts a new row into the
jobstable to describe what to run - Inserts a new row into the
job_runstable to represent this specific execution attempt, withstatus = queuedandavailable_at = now()
This atomic write ensures that either both rows exist (and the job can run) or neither (no inconsistent state).
Step 4: Enqueue the Job for Execution
Once the job is recorded and eligible, the scheduler publishes it to the job queue. This decouples job creation from execution and allows workers to pull jobs as needed — without polling the database.
Step 5: Worker Claims and Executes
When a worker begins processing a job, it must first secure exclusive rights to that job to prevent concurrent execution by other workers. This is achieved through a lease-based ownership model.
5.1: Pull the job: The worker retrieves the next available job — either by pulling from a queue or receiving it through a push-based delivery mechanism.5.2: Lease acquisition: The worker calls into the job run metadata to claim a lease on the specific run_id. Before running the job, the worker must claim it in the job run metadata store.This step prevents two workers from executing the same job simultaneously.
claimed_byTEXTNULLABLEWorker ID that leased it.claimed_atTIMESTAMPTZNULLABLELease start.lease_expires_atTIMESTAMPTZNULLABLEWhen others may safely steal it.
5.3 Atomic state flip: The lease acquisition and job status update happen in the same transaction:
- Set
claimed_by,claimed_at, andlease_expires_at - Change
job_run.statusfromqueued→running
This atomic operation ensures:
- No two workers can claim the same job simultaneously
- The job’s lifecycle state is always consistent with its lease ownershi
5.4 Execute the job: Once the lease is secured, the worker begins execution.
Execution must be idempotent wherever possible — meaning that if the job is retried (due to crash, timeout, or failover), repeating it won’t cause unintended side effects (e.g., sending duplicate emails, charging twice). Details of idempotent design are covered in Deep Dive 4 (DD4)5.5 Renew the lease: For long-running jobs, the worker must periodically extend the lease (heartbeat) before it expires.
If the worker fails to renew:
- The lease expires
- Another worker may safely steal and re-run the job
The specifics of heartbeat intervals and renewal mechanisms are discussed in Deep Dive 6 (DD6).
Step 6: Execute the Job
With the lease secured, the worker performs the task. If the job is long-running, the worker sends heartbeats to extend the lease before expiration.
Step 7: Complete or Retry
- On success, the worker marks the run
succeeded. - On retryable failure, the worker records
failed, creates a newjob_runwith an increased backoff (available_atin the future), and re-enqueues. - This preserves the original intent while keeping each attempt auditable.
DB schema design
When you design a scheduler component (whether for immediate, or maybe later to support delayed, or recurring execution), having two separate tables — jobs and job_runs — isn’t just a nice-to-have, it’s the backbone for traceability, retries, and scaling execution safely.
Jobs — the what
Holds the definition (type, payload, policy). It changes rarely and anchors idempotency and ownership.
Job_runs — the when & how it happened
One row per attempt (including retries)- the execution ledger that powers leasing, retries, and analytics.
SQL vs NoSQL for the Core Store
A relational database (e.g., PostgreSQL or MySQL) is a strong choice for the system of record. It offers:
- ACID + constraints: atomic write of
job+job_run, foreign keys for lineage, unique/partial indexes for idempotency (e.g.,UNIQUE(dedupe_key) WHERE dedupe_key IS NOT NULL). - Worker-safe concurrency:
SELECT … FOR UPDATE SKIP LOCKEDenables safe claiming with high parallelism; leases map cleanly to row updates. - Right indexes for hot paths: partial indexes on status subsets (e.g.,
status='queued') keep ready-pick scans tiny; BRIN/partitioning handle large, time-orderedjob_runs.
NoSQL systems (like Redis or DynamoDB) are great for coordination — leases, heartbeats, rate limits — but fall short for long-term tracking, history, and consistency guarantees. They lack:
- Multi-row transactions
- Foreign key enforcement
- Efficient time-based queries
By establishing immediate job execution first, we create a resilient, debuggable, and extensible foundation — one that scales naturally to support future and recurring jobs, and powers reliable infrastructure at scale.
FR2: Support job on a future or recurring schedule
Once immediate job execution is well established, the natural next step is to expand the scheduler to support time-based execution — that is, jobs that run at a specific future moment or on a recurring cadence (e.g., "every Monday at 8:00 AM"). This additional capability is crucial for supporting long-term automation, routine data processing, and workflow orchestration in enterprise environments.
To implement this functionality reliably and precisely, we need to think carefully about when jobs fire and how accurately they align with their intended schedule. There are three key dimensions to focus on:
- Trigger accuracy — how close the start time is to the planned time (e.g., fire at 10:00:00 as planned schedule, but not 10:07:00).
- Jitter — the small, load-induced variation around that target (tiny, unavoidable drift you want to keep bounded).
- Burst handling — what happens when many schedules fire at once (second-boundary fan-outs); the system must smooth spikes without going late.
Core strategy (DB-driven scan)
At the heart of time-based scheduling lies a relatively simple but effective mechanism: the database-driven horizon scan. Here’s how it works:
- Run a lightweight background scheduler process that continuously scans the
jobstable. - Identify active schedules — that is, jobs with
next_fire_atless than or equal tonow + horizon(e.g., 2–5 minutes in the future). - For each eligible job:
- Materialize exactly one
job_runoccurrence (if one doesn't already exist) - Advance the
next_fire_atto the next scheduled time (e.g., based on cron or interval rules)
- Materialize exactly one
This mechanism provides:
- High visibility into upcoming work
- Flexibility in batching and fairness
- A reliable base for recurring schedules without depending on external triggers

End-to-end flow
1. Scan due jobs
The first step is to identify which jobs are eligible to run within the near future. The scheduler performs a periodic query:
2. Advance the schedule
For each processed row, compute the next next_fire_at from the last scheduled fire (timezone/DST aware). If further occurrences still fall within the horizon, they’ll be picked on subsequent due job scan.
3. Advance the Schedule
Once a run is materialized, you must compute and update the next occurrence (next_fire_at) of that job.
- This must be timezone- and DST-aware, especially for human-facing cron jobs
- If the next occurrence also falls within the current scan window, it will be picked up in the next iteration
4. Publish to the job queue
There are three common options to publish a job once it’s ready:
Option 1 — Direct publish (best-effort timing)
You push the job to the queue immediately as soon as it’s ready:
- Workers must still check that
available_at <= now() - Timing is best-effort; you may see some drift
- Works well when exact precision isn’t critical
Option 2 — Native delay (queue-enforced)If the queue supports delayed delivery (e.g., AWS SQS, RabbitMQ with TTL):
- Publish immediately with a delay =
max(0, available_at - now) - Broker will hold the message and release it at the correct time
- Workers must still enforce
now >= available_atand respect cancellation
Trade-offs:
- Accuracy depends on broker delay resolution and SLA
- Max delay limit (e.g., 15 min or 15 days depending on queue)
Option 3 — Outbox with relay (relay-enforced)If your queue doesn’t support native delays, or you want tighter control:
- Use the Transactional Outbox Pattern:
- When materializing a
job_run, also write anoutboxrow (e.g.,event = run.ready) in the same DB transaction - A stateless relay process later scans unsent outbox rows and decides when to publish
- When materializing a
Relay acts as the time gate:
- Optionally hold until
available_at <= now - Add jitter to smooth second-boundary bursts
- Honor cancels or reschedules by skipping or editing outbox before publish
Relay guarantees:
- No lost or phantom messages (DB and publish are atomic in effect)
- Easier to implement graceful retries and backoffs
5. Workers execute and close the loop
Once the job is published:
- The worker leases the job_run by run_id
- Re-checks
available_at, cancellation flags, or idempotency guards - Executes the job logic
- Writes terminal status (
succeeded,failed,canceled, etc.)
On retryable failures:
- Materialize a new
job_runwith exponential backoff - Re-enqueue it via any of the strategies above
- Acknowledge only after durable state is persisted
FR3: System Healthy Monitor
Monitoring system health lets you spot problems before users do, keep SLOs honest, and fix issues fast by pinpointing where lag or errors occur across scheduler → outbox/relay → queue → workers → DB. It guides autoscaling and cost control, protects correctness (idempotency, leases), maintains tenant fairness, and provides an auditable record of what ran and when—turning the scheduler into predictable, reliable infrastructure.
What to measure (and why)?
- Scheduling lag = (publish_time or release_time) − available_at — p95/p99 show if you’re late at the time gate (relay/queue).
- Start lag = first_lease_time − available_at — isolates worker pickup delays (capacity, hot partitions).
- Outbox backlog — unsent rows over time; sustained growth = publish failures or relay under-provisioning.
- Retry funnel — attempts per run, DLQ volume, top error codes; tells if failures are transient vs. systemic.

Where to instrument (single span per stage)?
- Scheduler: job and job run
available_at,occurrence_timetimestamps. - Job Run/Outbox/Relay: stamp
created_at,published_at(and effective release_time if delayed). - Queue: queue depth, oldest-ready age, per-partition lag.
- Workers:
first_lease_time,started_at,finished_at, result, attempt#, error_code. - DB: ready-run count, running with expired leases, index scan vs. table hit ratios.
Use the metrics to pinpoint where latency or errors originate and take targeted action.
- The flow view (scheduling lag → start lag → runtime) tells you whether delays are at the time gate, pickup, or execution.
- The capacity view (queue depth, worker concurrency, CPU/mem utilization) drives autoscaling and partition rebalancing.
- The stability view (job_run (or even outbox) backlog, publish errors, redeliveries, lease rescues, DLQ reasons) flags relay/broker issues, bad leases, or poison jobs.
Deep Dive
DD1: The system should support up to 10k job executions per second
Once you move beyond prototypes and toward real-world, production-grade systems, performance bottlenecks start to emerge—especially in high-throughput environments. Supporting up to 10,000 job executions per second is a true stress test for any scheduler. To meet this goal, let’s walk through three of the most critical scalability levers: the job metadata database, the job publishing layer, and the queue-worker execution layer.
- Job Metadata DB
Every job touches the database multiple times throughout its lifecycle:
- When the job run is created
- When it is published or picked up by a worker
- When execution completes and the status is written
At a throughput of 10,000 jobs per second, that translates to roughly 20,000–30,000 database writes per second. This volume demands a storage layer that is optimized for speed, concurrency, and lifecycle management.
Key tactics:
- Design schema and indexes to favor hot paths like
status='queued' AND available_at <= now()to optimize for job selection - Use partial indexes to keep the indexed set small
- Adopt time-based partitioning (daily/weekly) so historical
job_runscan be efficiently dropped or archived - Use
job_idas the partitioning key to enable distribution across shards for large-scale execution
This lays the foundation for both high throughput and operational resilience.
2. Job Publishing Layer
Your system must reliably and continuously materialize job_runs and publish them to the job queue. This path must keep up with creation rate or else jobs will accumulate in the DB and execution will stall.
To achieve this:
- Horizontally scale the scheduler services that generate job_runs and enqueue them
- But this raises a concern: with multiple schedulers running in parallel, how do we prevent the same job from being enqueued multiple times?
3. Queue & Worker Cluster
The final leg of execution is where jobs are picked up, executed, and closed out. To handle massive volume and variance in job execution time, you must design a queue and worker cluster with scale and fairness in mind.
Key design choices:
- Create hundreds of partitions in the job queue (512–1024) to eliminate contention and allow maximum parallelism
- Monitor per-partition metrics, such as “oldest ready job age,” to detect skew or lag
- Size the worker pool as:
By carefully optimizing these three layers—metadata persistence, job publishing, and queue/worker infrastructure—your scheduler can scale confidently to meet the 10,000 jobs/sec target. Each lever reinforces the others, and tuning them in concert enables reliable, high-throughput execution across diverse workloads and tenants.
DD2: How to improve fault tolerance of the job scheduler?
When building a job scheduler designed to operate reliably at scale, fault tolerance isn't optional—it’s a first-class requirement. In distributed systems, things inevitably go wrong: worker nodes crash, queues experience hiccups, network links drop packets, and services intermittently become unavailable. What separates robust systems from brittle ones is their ability to recover from failure gracefully while still honoring job execution guarantees like at-least-once or even exactly-once effects (to be expanded in DD4).
To achieve this, the retry mechanism must be thoughtfully designed—not as an afterthought, but as a core architectural pillar.
Retry Model
Every job_run should be resilient to crashes, replays, and infrastructure blips.
- Unique identity: Each retry attempt should tie back to the same
job_id, forming a logical chain of attempts. - Retry tracking: Maintain a dedicated
attemptfield injob_runsso you can differentiate between a first execution and a fourth retry. - Idempotency by design: All side effects (especially those outside your system, like database writes, billing systems, or API calls) must support safe replays. This is often enforced via an idempotency key, typically formed by combining
job_id + scheduled_atorjob_id + run_number.
To retry a failed job:
- Insert a new row in
job_runswithattempt += 1 - Preserve the same
job_idand idempotency key - Track the lineage for observability and postmortem analysis
This separation enables a complete history of failures, retries, and eventual success—while ensuring downstream systems are not impacted twice.
Retry Controls: Timing, Budget, Classification
Retry logic must go beyond just "try again later." It needs to be shaped by policies that balance recovery with system stability. These include timing, budget constraints, failure classification, and clean state transitions.
1. Timing & Backoff
- Use exponential backoff with jitter:
- For example: 1s → 2s → 4s → 8s … with added randomness
- Prevents retry storms ("thundering herd") where thousands of jobs retry simultaneously
- For latency-sensitive workloads, cap maximum backoff (e.g., never delay longer than 60 seconds)
2. Retry Budgets
- Define maximum retry attempts per job (e.g., 5)
- Or use time-based retry windows (e.g., retry only for the next 15 minutes)
- Once the retry budget is exhausted:
- Mark the job as GIVE_UP
- Optionally move to a Dead-Letter Queue (DLQ) for offline debugging, alerting, or manual triage
3. Failure Classification
All failures are not equal. Categorizing them helps prevent wasteful retries.
- Retryable (transient):
- Network timeouts
- 5xx service errors
- Worker crashes or infra issues
- Non-retryable (permanent):
- Invalid input
- Validation failures
- 4xx errors from external services
Classify failures explicitly using error_code and error_type in job_runs. Retry only the failures that have a reasonable chance of succeeding the next time.
4. State Transitions & Audibility
Retries should not mutate the existing job_run. Instead, they must be modeled as new, discrete attempts:
- Transition from:
- FAILED → SCHEDULED (new run, attempt += 1)
- This ensures:
- Each attempt is auditable
- Downstream systems can be alerted to repeated failures
- Histories can be aggregated per
job_idfor trend analysis or debugging
By building fault tolerance into the core execution loop—not just at the edge—you create a scheduler that is robust under pressure, recoverable under failure, and transparent under analysis.
This retry architecture ensures your system is not only correct but also resilient, giving your engineering team and stakeholders confidence in your job infrastructure’s ability to survive the real-world chaos of distributed computing.
DD3: Tighter trigger accuracy or schedule time critical events
In high-volume and time-sensitive systems, precise job scheduling is not just a performance optimization—it is a business requirement. Whether it's executing an ad auction at a specific millisecond, activating a pricing rule at market open, or launching a flash sale at a synchronized time, trigger accuracy becomes critical. In this section, we explore how to reduce the gap between when a job is supposed to fire and when it actually gets executed, especially at the P95 percentile.
To do this, a robust job scheduler needs to actively control for the three major latency contributors:
- Jitter (random drift from target time)
- Queuing delays (congestion at the handoff point)
- Clock precision (differences across distributed systems)
Let’s walk through three implementation strategies—from managed services to in-memory schedulers—that offer different tradeoffs between precision, complexity, and operational overhead.
Option 1: Use Managed Delay Queues for Simplicity
If your timing SLOs are forgiving (e.g., 0.5 to 2 seconds of acceptable delay), then using managed delay queues is often the best choice. Tools like AWS SQS, Google Cloud Tasks, or delay-enabled Kafka topics provide simple primitives like deliver_after or not_before timestamps. Once you enqueue a job, the provider ensures it becomes visible near the scheduled time.

Benefits:
- P95 trigger accuracy in the 100 ms–2 s range, more than adequate for most business tasks (emails, user-facing workflows, etc.)
- Zero-to-minimal operational effort: the provider handles durability, dead-letter queues, and retry backoffs out of the box
- Infinite scalability with little need for sharding, rebalancing, or leader election logic
Tradeoffs:
- Limited timing precision—jitter floors around hundreds of milliseconds to a few seconds
- No fine-grained retry policy control (e.g., microsecond retries or custom jitter algorithms)
- You must design for idempotency in workers since retries and delayed visibility can cause reprocessing
- Vendor lock-in for some queues (e.g., SQS delay limits or SLA granularity constraints)
Option 2: Build a Fast Loop for Sub-100ms Accuracy
When your SLO demands sub-second or even sub-100 ms trigger accuracy, especially for financial, fraud, or auction systems, then the scheduler must avoid all external latency. In this model, each scheduler node maintains a RAM-resident heap of jobs that need to fire within the next W seconds (e.g., W = 60). It uses a local timer loop to pop jobs at the precise microsecond they are due.

Benefits:
- Sub-100 ms P95 trigger time possible
- Zero reliance on queue latency or DB polling intervals
- Allows you to batch fire events at precise time boundaries (e.g., 10:00:00.000)
- Perfect fit for use cases like:
- Ad auctions / market events
- Real-time fraud prevention rules
- Flash token drops
Tradeoffs:
- State is ephemeral: a crash causes all in-memory timers to vanish
- You must rebuild the near-future window from persistent job metadata on restart
- Requires careful clock management and fencing logic across replicas to avoid multiple nodes firing the same job
- High ops complexity: you now manage event loops, sharding, backpressure, crash recovery, and fencing tokens
Option 3: Adopt a Hybrid Slow-Lane + Fast-Lane Job Queue
The hybrid model is a popular production-grade design that blends precision with durability. In this setup:
- All jobs are durably persisted in a DB (or Kafka stream) as the source of truth
- Each scheduler node maintains a rolling fast window in memory (the "fast lane") to handle jobs due in the next few minutes
This gives you the ability to:
- Execute high-precision triggers for jobs in the near future
- Retain durability and safety for longer-term scheduled jobs
Benefits:
- Good balance of operational safety and tight timing
- Windowing strategy enables efficient recovery after crash (just reload
available_at ≤ now+W) - Best fit for mixed workloads: e.g., market close (accurate) + background ETL jobs (tolerant to delay)
Tradeoffs:
- Complex edge-case handling when jobs fall right on the edge of the memory window
- Clock skew across replicas must be strictly bounded via NTP or PTP
- Requires tight coordination between durable layer (DB/Kafka) and volatile fast loop
Optimizing trigger accuracy isn’t just about firing jobs on time—it’s about making sure they’re executed promptly once triggered. During load spikes or bursts, you don’t want latency-critical jobs (e.g., fraud triggers, flash sales) stuck behind background jobs (e.g., email sends, data syncs). A priority-aware queueing system ensures your most urgent jobs don’t get delayed.

The design choice depends on your trigger latency SLO, operational budget, and the nature of your job workloads:
- For simplicity at scale: managed queues (Option 1)
- For sub-100 ms SLOs: RAM-resident fast loop (Option 2)
- For long-range safety and short-range precision: hybrid model (Option 3)
Always pair accurate scheduling with priority-aware queues and idempotent worker logic to ensure not just on-time triggers—but on-time execution.
DD4: Delivery semantics
Support modeling delivery semantics in your scheduler’s config—so each job can declare at-least-once, at-most-once, or the (practical) exactly-once illusion and get the right runtime behavior, safeguards, and metrics.

At-most-once
You may lose a delivery (e.g., crash between send and commit), but you will not duplicate it. No retries (or only before acknowledging receipt).
When job scheduler is configured as at-most-once, the worker ACKs before doing any work, it tells the broker “this message is handled.” The broker removes it from the job queue right away. If the worker then crashes mid-processing, the broker has nothing left to redeliver—so you get at-most-once delivery (no duplicate redelivery from the queue).
At-least-once
You may see duplicates, but you should not lose a delivery. Retries are enabled, and the worker ACKs only after the effect is durably committed. If the worker crashes mid-processing, the job queue will redeliver the job; if your worker cluster handler supports idempotent so replays are harmless, and your system becomes exact once. There are some details about how it works in a job scheduler:
- Ack after commit: The worker update job status and lift a contract, commits them, then ACKs. If it crashes before ACK, the broker redelivers; if it crashes after commit but before ACK, the job may run twice—idempotency absorbs the duplicate.
- Queue semantics: Use a visibility timeout (SQS/RabbitMQ) or commit offsets after processing (Kafka). While a worker is handling the message, it stays hidden (or the offset isn’t committed).
- Retries: On retryable errors (timeouts, 5xx, rate limits), NACK with exponential backoff + jitter. After a max attempt budget, send to DLQ with full context.
Exactly-once (the illusion)
Exactly-once effects (practical): the observable outcome happens once, even if messages are duplicated or retried. You get this by combining at-least-once transport with idempotent handlers—and, when needed, a transactional boundary.
- Scheduler side: run in at-least-once mode (visibility/offset commit after work, retries, ACK after commit).
- Worker side: enforce idempotency (stable idempotency key + dedupe/UPSERT/CAS) so replays are harmless.
- Optional transactions: use outbox/inbox (same DB) or Kafka EOS to bind reads/writes/offsets atomically.
Put together, duplicates are delivered but absorbed, so the effect is applied exactly once.
DD5: Job Dependencies and Orchestration
Real systems rarely run a single job in isolation. You need to express “do C after A & B succeeds,” fan out many tasks in parallel, then fan in to an aggregate, handle retries without double-running children, and keep runs reproducible even when the pipeline definition changes mid-flight. The key is to extend your existing scheduler with a DAG-aware orchestration layer that is versioned, race-safe, and idempotent.
Core Concept:
Jobs vs. Tasks vs. Runs. Keep the definition/execution split. A DAG (pipeline) is a versioned set of tasks (nodes) and edges (dependencies). Each Dexecution creates a DagRun, and each task in that DAG creates a TaskRun. Like Job vs JobRun, orchestration logic (pre-req tracking, fan-in counters, retries) lives on TaskRun.
Determinism & idempotency. A child task should start exactly once per parent-run outcome even under retries, failovers, or duplicate messages. Use (dag_run_id, parent_task_run_id, edge_id) as a unique key for child creation; use version/fencing for state transitions.
You keep the same dispatcher/worker model. The orchestrator is a thin control loop that turns “task is now READY” signals into JobRuns in your existing system; workers remain unchanged.

- A DagRun is created (by schedule, event, or manual trigger) and its root tasks are marked READY.
- For each READY task, the orchestrator creates a JobRun (or enqueues a message) in the original system.
- Workers execute Job Runs normally (including leases, heartbeats, checkpoints for long steps).
- When a Job Runs reaches a terminal state, the orchestrator updates successor counters. If a successor’s
remaining_prereqs = 0(and any extra conditions are met), mark it READY and dispatch. - The DagRun completes when all terminal nodes finish or a failure policy halts the graph.
Nothing major change required. You reuse jobs (definitions) and job_runs (execution) as-is. The orchestrator creates a job_run whenever a task_run becomes READY, then links it via task_runs.job_run_id.
DD6: How to support Long-Running Jobs?
A long-running job should have a single owner at any moment, prove it is still alive, make forward progress visible, be able to stop safely on request, resume after failure without starting from zero, and recover automatically if its worker disappears. Achieve this with three primitives: leases + heartbeats, progress + checkpoints, and visibility timeouts:
- Leases + Heartbeats (ownership & liveness): A worker that claims a
JobRuntakes a lease (owner + expiry) and sends periodic heartbeats to extend it. This prevents duplicates, quickly detects crashes/partitions, and bounds cancel latency because a soft cancel is honored on the next heartbeat. - Progress & Checkpoints (resumability): With ownership established, the worker regularly records progress (stage/percent) and persists checkpoints (durable resume points like offsets, segments, or snapshots). This enables resume after failure/cancel without redoing hours of work, makes soft cancel safe, and supports idempotent replays.

- Visibility Timeout (single consumer, auto-recovery): While a run is being processed, its queue message is hidden and the worker extends visibility on each heartbeat (or uses a DB row lease TTL). This guarantees one active worker per run and ensures automatic re-delivery if the worker dies.
On the data side, add ownership and progress fields to job_runs: a lease (claimed_by, claimed_at, lease_expires_at) plus liveness (last_heartbeat_at), resumability (progress, checkpoint_uri), control (cancel_requested), attempt count, and a monotonic version for optimistic concurrency. Configure your queue or table so visibility/lease TTL ≈ 2–3× heartbeat; workers extend it every heartbeat to keep single-consumer semantics and allow automatic recovery if they disappear.