Functional Requirements
FR1 – Ingest & Update Player Scores
- The system must accept score updates for a player on a given leaderboard.
- Input includes:
player_id,leaderboard_id(game / mode / region / period), andnew_scoreplus an idempotency key (e.g.,match_id). - The system must maintain a non-decreasing integer score per
(player_id, leaderboard_id).
FR2 – View My Global Rank & K Neighbors
- Given
player_idandleaderboard_id, the system must return:- The player’s current score.
- The player’s current global rank.
- Up to K players above and K players below the user on the global leaderboard.
- Must handle edge cases (player near top/bottom → fewer than K neighbors).
- Results should reflect recent updates in near real-time (tied to our <500 ms update SLO).
FR3 – View K Friends Around Me
- Given
player_id,leaderboard_id, andK, the system must return:- The player’s rank and score within their friends-only leaderboard.
- Up to K friends above and K friends below them.
- Uses an external friends/social graph as input; our service filters or indexes rankings based on that list.
FR4 – View Top-N Leaderboards (Global / Regional / Time-Windowed)
- Given a
leaderboard_idandN, the system must return the top-N entries (player_id, score, rank) for that leaderboard. - Must support multiple scopes via
leaderboard_id:- Global (per game / per season, all regions).
- Regional (e.g., NA / EU / APAC).
- Time-windowed (daily / weekly / monthly / seasonal, each with a strict start date).
- Used for classic “Top 100 / Top 1000” views and tournament pages, and should refresh near real-time as scores change.
Non-Functional Requirements
NFR1 – Correctness & Determinism
- A player’s score on a leaderboard is never lost, mis-ordered, or double-counted.
- Updates are monotonic and idempotent per
(player_id, leaderboard_id)(e.g., keyed bymatch_id).
NFR2 – Real-time Freshness & Latency
- Write → visible rank (unchanged):
- p95 ≤ 500 ms, p99 ≈ 1 s for the player’s own score.
- Read APIs (my rank, neighbors, top-N), server-side:
- p95 ≤ 100 ms, p99 ≤ 500 ms.
- It’s fine if some pages (e.g., big top-N lists) sit closer to the tail; players experience this as “instant enough” as long as it’s clearly under ~0.5–1 s end-to-end including network.
NFR3 – Availability & Graceful Degradation
- Leaderboard reads and score updates: ≥ 99.9% availability.
- Under failures, prefer serving last-known data (cached rank / top-N) over errors.
- If degraded, surface simple hints like “last updated X seconds ago” instead of breaking UX.
NFR4 – Scalability & Hotspot Resistance
- Handle 100–300M score updates/day → peak around 10K updates/sec.
- Handle ~1B leaderboard reads/day (~5× writes).
- Sharding / caching must avoid any single hot shard (e.g., top of global board or celebrity profiles) becoming a bottleneck.
- System scales horizontally by adding nodes, not by vertically beefing up a single box.
High Level Design
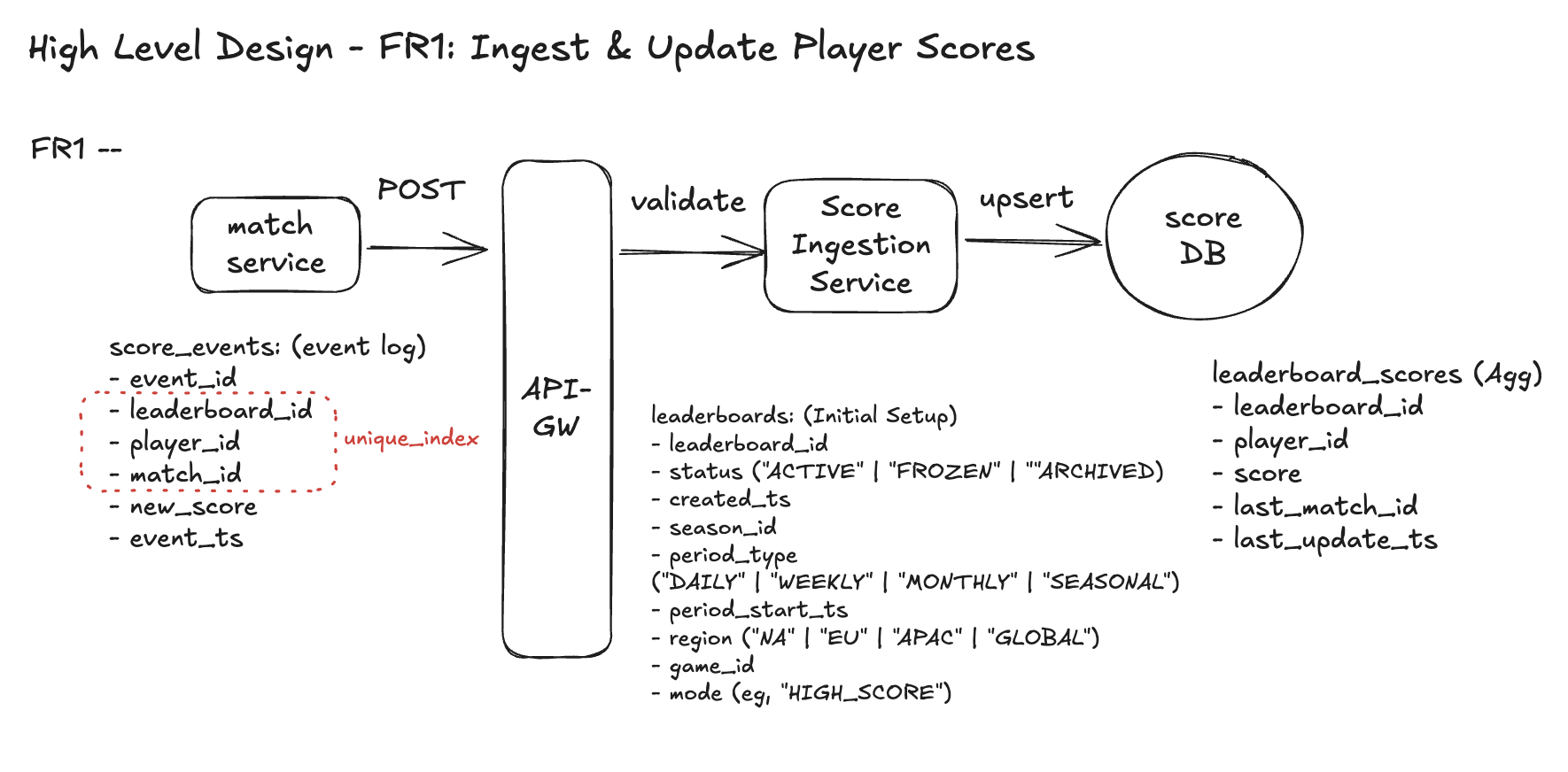
FR1 – Ingest & Update Player Scores
API (Abstract)
We’ll assume the game backend calls us after each match.
1. Endpoint (abstract)
2. Response (example)
Core Entities
1.leaderboards
- Describes one concrete leaderboard: game + mode + region + season + time window.
- Tells us where a score update should go and whether that leaderboard is active.
- Encodes score policy so we know we’re in the
HIGH_SCOREworld (monotonic best-score).
2. score_events (append-only log of raw updates)
- Logs every match event that tried to update a leaderboard.
- Useful for audit, debugging, and later replay / rebuild if needed.
- Enforces uniqueness on
(leaderboard_id, player_id, match_id)so the same match can’t be ingested twice.
3. leaderboard_scores (canonical per-player state)
- Holds the current visible score per
(player, leaderboard). - This is the row all future FRs will query for:
- My score, my rank, K neighbors, top-N, etc.
- Encodes the HIGH_SCORE, monotonic semantics and idempotency.
Workflow
Step 1 - Match service sends score update
- After a match, the match service
POSTtheleaderboard_id,player_id,match_id,new_scoreto API-GW.
Step 2 - API-GW routes to Score Ingestion Service
- API-GW does auth / basic validation and forwards the request to the Score Ingestion Service.
Step 3 - Score Ingestion validates leaderboard & logs event
- Checks that the
leaderboard_idexists and isACTIVE. - Inserts a row into
score_events(leaderboard_id,player_id,match_id,new_score,event_ts). - The unique index on
(leaderboard_id, player_id, match_id)enforces idempotency (duplicate match → treated as retry).
Step 4 - Apply HIGH_SCORE rule using leaderboard_scores
- Reads current row for
(leaderboard_id, player_id)fromleaderboard_scores. - If
match_id == last_match_id→ retry, no change. - Else if
new_score <= current score→ not a new high score, no change. - Else → update
leaderboard_scoreswithscore = new_score,last_match_id = match_id,last_update_ts = now().
Step 5 - Respond back to match service
- Score Ingestion Service returns final
score,previous_score,last_match_id, andupdate_applied = true/false→ API-GW → match service.
Design Diagram
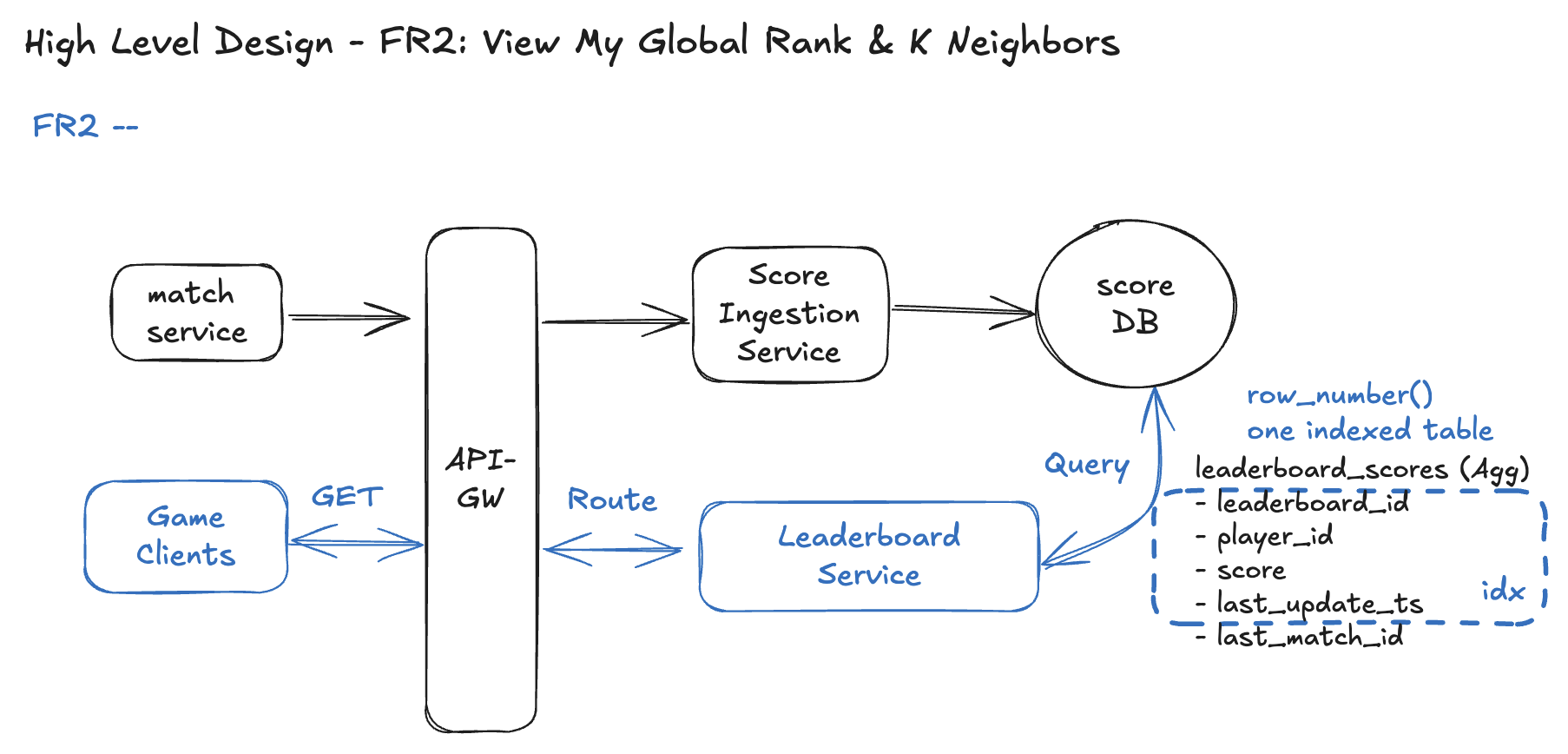
FR2 – View My Global Rank & K Neighbors
APIs
Query params
k– how many neighbors above and below to return (e.g.,k=2→ up to 2 above + 2 below).
Response (example)
Behavior guarantees
- Uses the same HIGH_SCORE semantics as FR1 (score = best-ever in this period).
- Ranks are deterministic:
- Sort by:
score DESC, last_update_ts ASC, player_id ASC.
- Sort by:
- Handles edges (top / bottom of leaderboard) by returning fewer than k neighbors where necessary.
Core Entities
We reuse the entities from pre-defined ones; no new tables are required. To support deterministic ordering and rank queries from leaderboard_scores table:
Workflow
Step 1 - Client calls API-GW for my rank & neighbors
- Sends:
leaderboard_id,player_id,ktoGET /leaderboards/{leaderboard_id}/players/{player_id}/rank.
Step 2 - API-GW routes to Leaderboard Read Service
- Performs auth/basic checks, forwards to Leaderboard Read Service.
Step 3 - Read my current score & position input
- Leaderboard Read Service queries
leaderboard_scoresfor(leaderboard_id, player_id). - If no row → player is unranked (return 404 or
rank = null, depending on product choice). - If row exists → capture
my_scoreandmy_last_update_ts.
Step 4 - Compute my global rank & K neighbors (Single Table Case)
- Use a single ordered query over
leaderboard_scoresfor thisleaderboard_idwith deterministic ordering:ORDER BY score DESC, last_update_ts ASC, player_id ASC.
- Conceptually (or via a window function):
- Compute row_number for every player = their rank.
- Find my row_number =
my_rankby myplayer_id - Return rows where
rankis betweenmy_rank - kandmy_rank + k.
- This yields:
- My own row (with
rank = my_rank). - Up to
kplayers above andkbelow.
- My own row (with
Step 5 - Return rank + neighbors to the client
- Leaderboard Read Service builds the response:
global_rank = my_rank.score = my_score.neighbors = [players above, me, players below].
- Sends back via API-GW to the client.
Again, this keeps FR2 simple and correct:
- Single DB, no sharding/caching yet.
- Deterministic ranking based on
score,last_update_ts,player_id. - Clear vertical path ready to scale later (Redis sorted sets, sharding, etc.) when you get to the deep dives.
Design Diagram
FR3 – View K Friends Around Me
API
Query params
k– how many neighbors above and below to return within the friends set- (e.g.,
k=2→ up to 2 friends above + 2 friends below).
Response (example)
Behavior guarantees
- Uses the same
HIGH_SCOREsemantics as FR1/FR2 (score = personal best in this period). - Ranking is done only among the player’s friends (plus optionally the player themselves).
- Ordering is deterministic within the friend subset:
- Sort by:
score DESC, last_update_ts ASC, player_id ASC.
- Sort by:
- Handles edges:
- If you’re near the top or bottom of your friend leaderboard, you may see fewer than k friends above/below.
- Only friends who have a score row in this
leaderboard_idare counted infriends_totaland ranking.
Core Entities
We reuse existing leaderboard entities:
leaderboards– validateleaderboard_idand ensure reads are allowed.leaderboard_scores– get scores for the player and their friends.
And we introduce a simple friends graph owned by a Social Graph / Friends Service (logically a separate system, but we’ll show its table so the FR feels concrete):
friendships
Stored and managed by the Social Graph service. Our leaderboard only reads from it.
- Primary key can be
(user_id, friend_id). - For undirected friendships, you can either:
- Store two rows (
A,BandB,A), or - Store one row and query both directions; the exact choice isn’t critical for this HLD.
- Store two rows (
Workflow
Step 1 – Client calls API-GW for friends rank
- Game client sends
GET /leaderboards/{leaderboard_id}/players/{player_id}/friends-rank?k={k}- to API-GW.
Step 2 – API-GW routes to Leaderboard Service
- API-GW performs auth / basic validation.
- Forwards the request to the Leaderboard Service.
Step 3 – Fetch friend list from Social Graph
- Leaderboard Service calls Social Graph Service (backed by
friendshipstable): GET /players/{player_id}/friends.- Social Graph queries
friendshipsforuser_id = player_idandstatus = 'ACCEPTED'. - Returns a list of
friend_ids. - Leaderboard Service builds
friends_set = friend_ids ∪ {player_id}.
Step 4 – Compute friends-only rank and K neighbors
- Query
leaderboard_scoresfor thisleaderboard_idandplayer_id IN friends_set. - Drop any friends with no row (they haven’t played this leaderboard).
- Sort the remaining rows by:
score DESC, last_update_ts ASC, player_id ASC.- Assign 1-based rank within this list to get each friend’s friends_rank.
- Find
my_friends_rankforplayer_id. - Take entries where
rankis betweenmy_friends_rank - kandmy_friends_rank + k.
Step 5 – Return friends rank + neighbors
- Leaderboard Service builds the response:
friends_rank,friends_total,score, and theneighborsarray (friends above, self, friends below).
- Sends the response back to the client via API-GW.
Design Diagram

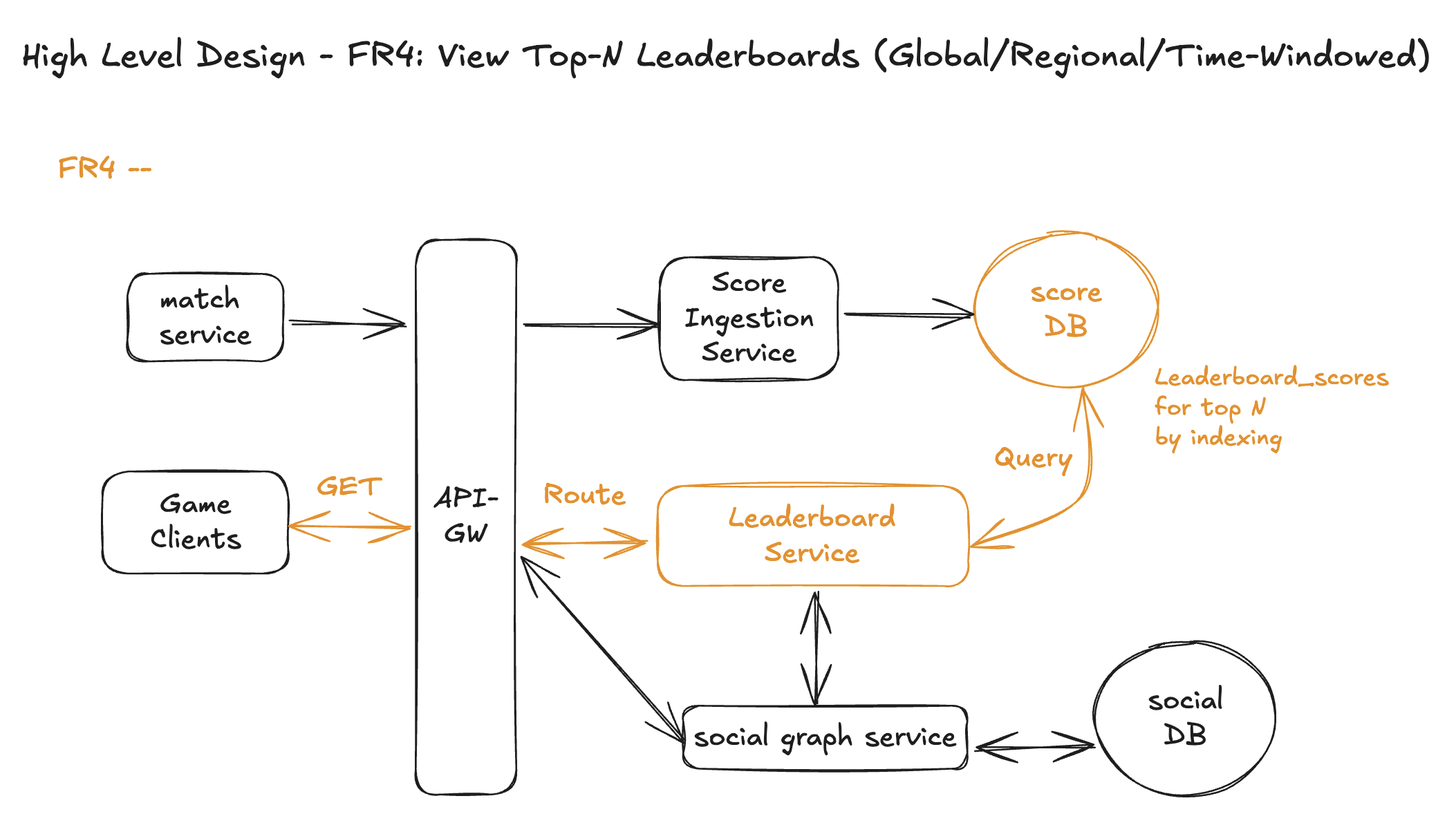
FR4 – View Top-N Leaderboards (Global / Regional / Time-Windowed)
API
Query params
n– how many top entries to return (e.g.,n=10).- Service enforces a max N (e.g., 100) and clamps larger values.
Response (example)
Behavior guarantees
- Uses
HIGH_SCOREsemantics (score = personal best in this period). - Top-N is per
leaderboard_id:- If that ID represents “Global / Season S12 / Daily 2025-11-18”, we only show that scope.
- Ordering is deterministic:
score DESC, last_update_ts ASC, player_id ASC.
- If
nis missing → use a default (e.g., 10). - If
n>max_n→ clamp tomax_n.
Core Entities
No change needed, we can skip here.
Workflow
Step 1 – Client calls API-GW for Top-N
- Game client sends
GET /leaderboards/{leaderboard_id}/top?n={N}- to API-GW.
Step 2 – API-GW routes to Leaderboard Service
- API-GW does auth / simple validation.
- Routes the request to the Leaderboard Service.
Step 3 – Validate leaderboard and normalize N
- Leaderboard Service looks up
leaderboardsbyleaderboard_id:- Ensures it exists and
status∈ {ACTIVE,FROZEN}.
- Ensures it exists and
- Optionally reads metadata (game, region, period) for logging / response.
- Normalizes
N:- Default if null (e.g., 10).
- Clamp to
max_nif too large.
Step 4 – Query Top-N rows from leaderboard_scores
- Runs an ordered query on
leaderboard_scoresusingidx_scores_rank:
- As results stream back, Leaderboard Service assigns 1-based ranks in order: 1, 2, …, N.
Step 5 – Build response and return to client
- Builds the response:
leaderboard_idtop_n = Nentries = [{ player_id, score, rank }...]
- Returns it to the client via API-GW.
Design Diagram
Deep Dives
DD1 – How to Maintain a Global Leaderboard at Billion Updates/Day Without a Hot Shard
Options to Discuss
Option A – Shard by leaderboard_id (simple, preferred when it fits)
- Each concrete leaderboard (
game + mode + region + season + period) lives in one sorted set on one ranking node (e.g., Redis ZSET): key = leaderboard_id.- All members of that leaderboard are on the same node:
- Top-N:
ZREVRANGE leaderboard_id 0 N-1. - “K around me”:
ZREVRANK+ZREVRANGE.
- Top-N:
- We then distribute leaderboards across many nodes:
node = hash(leaderboard_id) mod R.
Good when:
- Billion updates/day is spread across many leaderboards.
- Each single leaderboard’s QPS + cardinality fit comfortably on one node.
Option B – Shard by user_id inside a leaderboard (only if one board is too big)
- For a single massive
leaderboard_id, partition players byplayer_idacross S shards:shard_id = hash(player_id) mod S.
- Pros:
- Great write distribution, matches Kafka partitioning by user.
- Cons:
- Global range queries (Top-N, K-neighbors) now require an extra global index / aggregator to merge shards.
Useful only when one leaderboard truly can’t live on a single node.
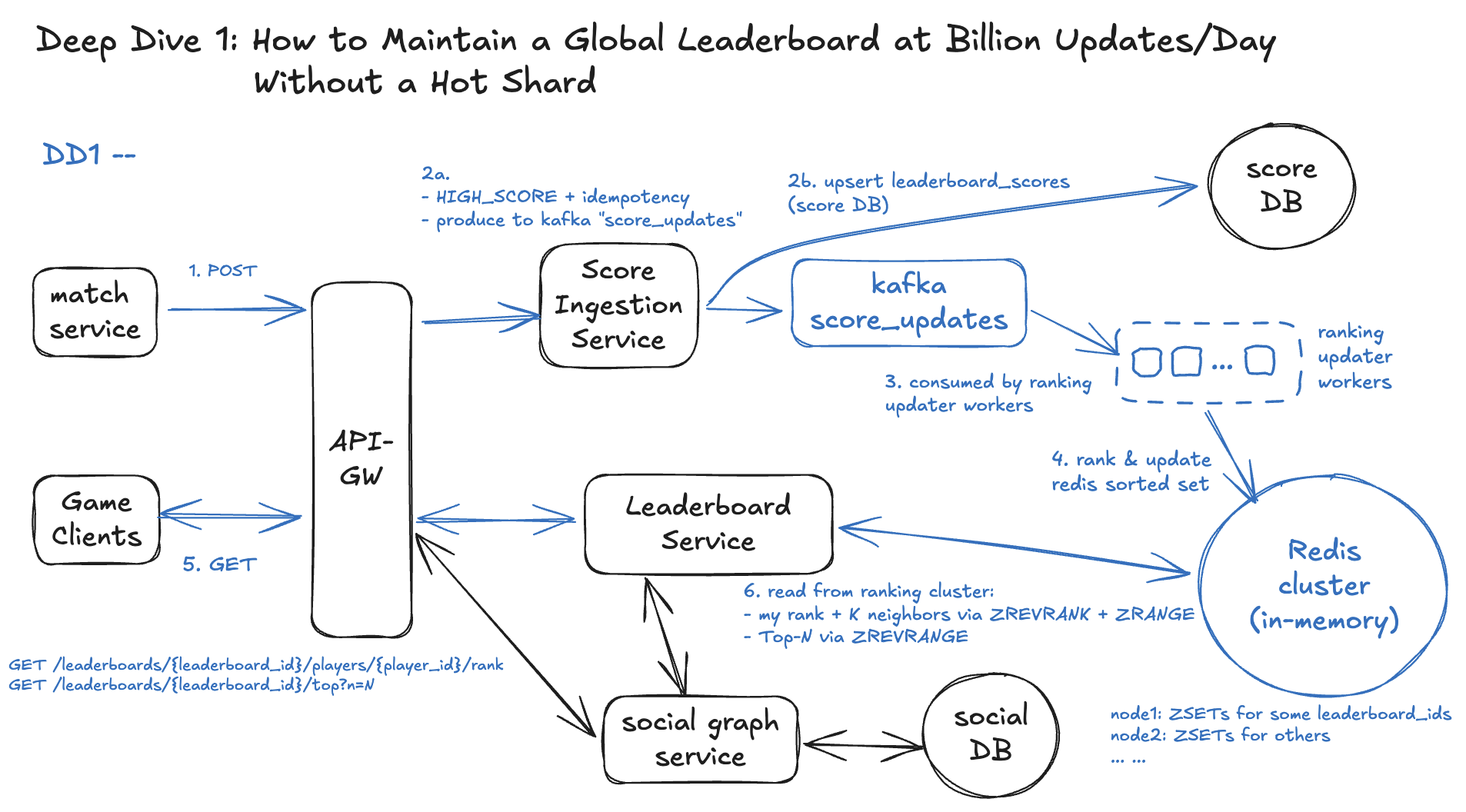
Final Solution: Ranking tier + per-leaderboard sharding.
Workflow
Step 1 - Score update comes in (same as HLD FR1 entry)
- Match Service →
POST /leaderboards/{leaderboard_id}/players/{player_id}/score→ API-GW → Score Ingestion Service.
Step 2 - Score Ingestion enforces correctness + writes DB + emits event
- Applies
HIGH_SCORE+ idempotency (FR1 logic). - Upserts
leaderboard_scoresin the score DB (canonical truth). - Publishes a message to Kafka topic
score_updateswith key =player_id, value ={leaderboard_id, player_id, new_score, last_update_ts}.
Step 3 - Ranking Updater consumes Kafka and routes by leaderboard
- Ranking Updater workers consume
score_updates. - For each event, compute
ranking_node = hash(leaderboard_id) mod R. - Send an update (e.g.,
ZADD) to that node for key =leaderboard_id, member =player_id.
Step 4 - Ranking Cluster maintains in-memory sorted sets per leaderboard
- Each node in the Ranking Cluster holds many sorted sets, one per
leaderboard_idit owns. - These sets are the authoritative in-memory rank index (exact order for Top-N and K-neighbors).
Step 5 - Read APIs (FR2/FR4) hit Ranking Cluster first
- Leaderboard Service (for “my rank + K neighbors” and “Top-N”) now queries the relevant
leaderboard_idsorted set in the Ranking Cluster. - DB is used for durability, cold recovery, and consistency checks—not for hot ranking queries.
So with our solution:
- FR2/FR3/FR4 will now read primarily from the Ranking Cluster, not directly from DB.
- This lets us handle billion+ updates/day across many leaderboards without a single hot shard, while keeping exact order and K-neighbor semantics.
Design Diagram
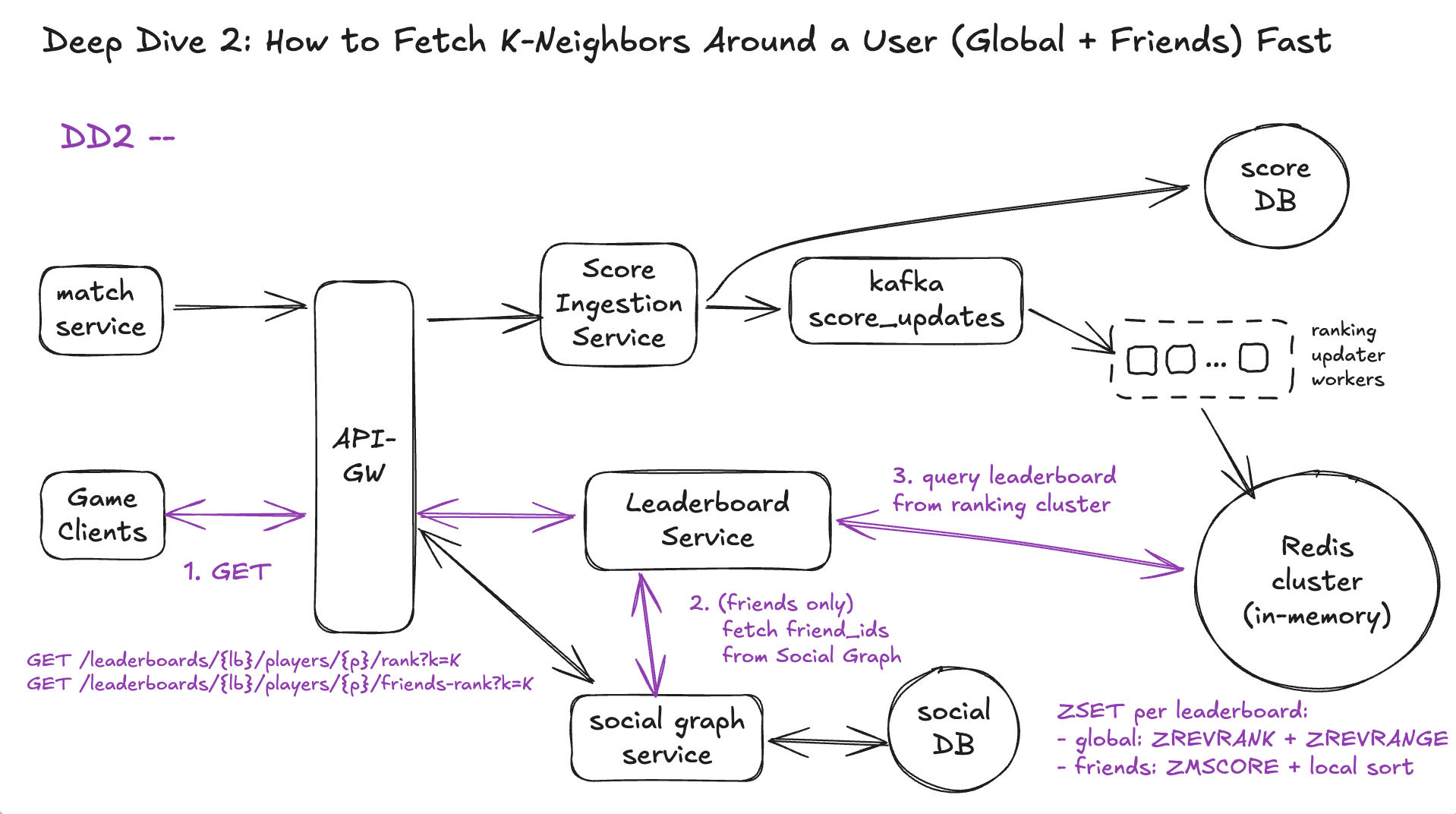
DD2 – How to Fetch K-Neighbors Around a User (Global + Friends) Fast
Options to Discuss
Read Path A. For global neighbors (FR2)
- DB window query per request – already rejected (slow, expensive).
- Use ranking cluster ZSETs
ZREVRANKto get the user’s index (rank).ZREVRANGEon[rank-K, rank+K]to get neighbors.- Time: ~
O(log N + K)and all in-memory.
Read Path B. For friends neighbors (FR3)
- Pre-materialized friend leaderboards per user
- Every score update fans out to all friends’ private boards.
- Completely impractical at 100M DAU → huge write amplification.
- Scan the leaderboard and filter to friends
- Obviously too slow (scan entire sorted set).
- On-demand intersection using ranking cluster + social graph
- Fetch friend_ids from Social Graph.
- Fetch each friend’s score from the same ZSET (batched).
- Sort friends locally by score and compute rank + K neighbors.
- Works because friend lists are typically small (O(10–100s)) even if the leaderboard has millions of entries.
We’ll pick:
- Global neighbors → ZSET rank + range.
- Friends neighbors → intersection of friend_ids with ZSET, done on demand.
Workflow – Global & Friends K-Neighbors (Combined)
- Client → API-GW → Leaderboard Service
- Global:
GET /leaderboards/{lb}/players/{p}/rank?k=K - Friends:
GET /leaderboards/{lb}/players/{p}/friends-rank?k=K
- Global:
- Build the target ID set
- Global:
id_set = { player_id }(we only care about this player for rank). - Friends: Leaderboard Service calls Social Graph → gets
friend_ids→ id_set = { player_id } ∪ friend_ids.
- Global:
- Talk to Ranking Cluster for this leaderboard
- Find ranking node:
node = hash(leaderboard_id) mod R. - Global:
idx = ZREVRANK(lb, player_id)neighbors = ZREVRANGE(lb, idx-K, idx+K, WITHSCORES)
- Friends:
scores = ZMSCORE(lb, id_set)(or pipelined ZSCORE)- Drop IDs with null score.
- Find ranking node:
- Compute ranks + neighbors
- Global:
global_rank = idx + 1- Neighbors = slice around
idxfromneighborslist.
- Friends:
- Locally sort
(id, score, last_update_ts)by score DESC, last_update_ts ASC, player_id ASC.- Assign
friends_rank= position in sorted list. - Take K above / K below the player.
- Locally sort
- Global:
- Return response via API-GW
- Global:
{ score, global_rank, neighbors[] } - Friends:
{ score, friends_rank, friends_total, neighbors[] }.
- Global:
This keeps DD2’s story tight:
- One ranking path (Ranking Cluster) for both global and friends.
- The only extra step for friends is the Social Graph lookup + local sort on a much smaller set.
Design Diagram
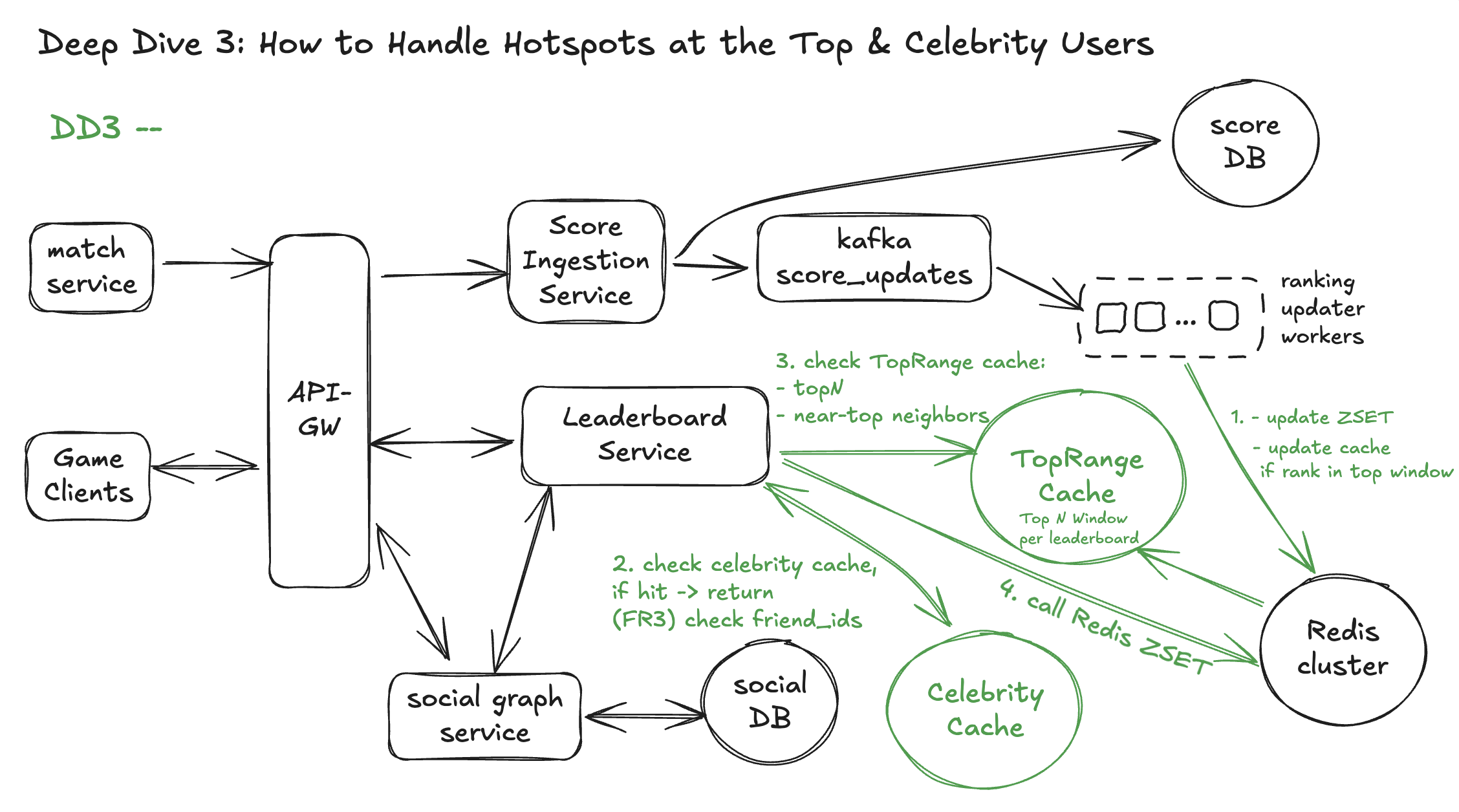
DD3 - How to Handle Hotspots at the Top & Celebrity Users
Options to Discuss
- Just scale up the hot ranking node
- Bigger instance, more CPU, maybe Redis replicas.
- Works to a point, but you’re still fundamentally centralizing all hot reads.
- Split the leaderboard further or multi-shard it
- Product-level splits: add regions/brackets; fewer players per board.
- Infra-level: promote that
leaderboard_idto a multi-shard configuration (user-id sharded + global aggregator, from DD1). - Powerful but more complex, and you don’t always need this.
- Add dedicated caches for “hot ranges” and “hot users”
- Precompute & cache Top-N / Top-K ranges off the ZSET and serve them from a lighter cache tier.
- Cache “celebrity: rank + neighbors” responses for a short TTL so thousands of fans share the same result.
- Back these with rate limiting / request coalescing so the ranking node doesn’t get hammered.
We’ll choose Option 3 as the default, with Option 2 as an escalation path if one leaderboard is still too hot.
Solution - Hot Range Cache + Celebrity Cache
1. Hot-range cache (for Top-N and “near the top”)
For each leaderboard_id we maintain a small top window (e.g., top 1000 players):
- When an update affects someone in the top window, the ranking node refreshes that slice once from the ZSET and writes it into a TopRange Cache (Redis / in-memory list).
- The TopRange Cache then serves:FR4 Top-N
- If
N ≤ hot_window_size, just read from TopRange Cache. - No ZSET call needed.
- If the user’s rank is within the hot window:
- Use
ZREVRANKonce to getidx. - Slice
[idx-K, idx+K]from the cached top window in memory (instead ofZREVRANGEon the ZSET).
- Use
- If
- Effect:
- Home-page “Top 10 / Top 100” traffic hits the cheap cache.
- The ZSET is used mainly for updates and occasional cache refreshes, not every read.
2. Celebrity “rank + neighbors” cache
At the Leaderboard Service layer, we add a tiny, short-lived cache keyed by:
- Value: the full FR2 result:
score,rank,neighbors[]. - TTL: very short (e.g., 200–500 ms).
So when a celebrity is hot:
- Thousands of viewers share the same cached response in that TTL window.
- The ranking node only sees one real query per window, not one per viewer.
We can do the same for friends view of a celebrity: cache
(leaderboard_id, celeb_id, friends_view) → friends_rank + neighbors with a short TTL.
3. Rate limiting + “upgrade” if still too hot
- Add per-user / per-IP QPS limits on FR2/FR4. If someone spams refresh, they get cached data or a gentle “slow down” response.
- If a specific
leaderboard_idis still too hot even with:- Top-range cache, and
- Celebrity cache, and
- Rate limiting
- Shard its players by
player_idacross multiple ranking nodes. - Use a small aggregator to merge shard top lists into a global Top-N and handle K-neighbors.
That way, we handle most hot cases with simple caching, and only pay the complexity of multi-shard ranking for the truly extreme leaderboards.
Workflow - Hotspots
Step 1 – Writes: same as DD1 + tiny extra
- Match → API-GW → Score Ingestion → Kafka → Ranking Updaters → Redis ZSET per
leaderboard_id. - If an update lands in the top window (e.g., top 1000), that ranking node:
- Refreshes
top_windowonce from the ZSET. - Stores it in **TopRange Cache[leaderboard_id]`.
- Refreshes
Step 2 – Reads: Leaderboard Service checks caches first
For FR2 / FR3 / FR4:
- Client → API-GW → Leaderboard Service.
- Celebrity cache (L1 at service layer):
- Key:
(leaderboard_id, player_id, K). - If hit → return
rank + neighborsimmediately.
- Key:
- Top-range cache (for Top-N + near-top):
- If
Nor the player’s rank is within the top window → slice from TopRange Cache.
- If
- If neither cache helps → use DD2 logic against Redis:
- Global:
ZREVRANK+ZREVRANGE. - Friends:
ZMSCORE+ local sort.
- Global:
- On miss, write result back to celebrity cache (short TTL) and respond.
Step 3 – Safety valves
- Per-user / per-IP rate limiting on FR2/FR4.
- If a specific
leaderboard_idis still too hot, promote just that board to the heavier multi-shard ranking design.
Design Diagram
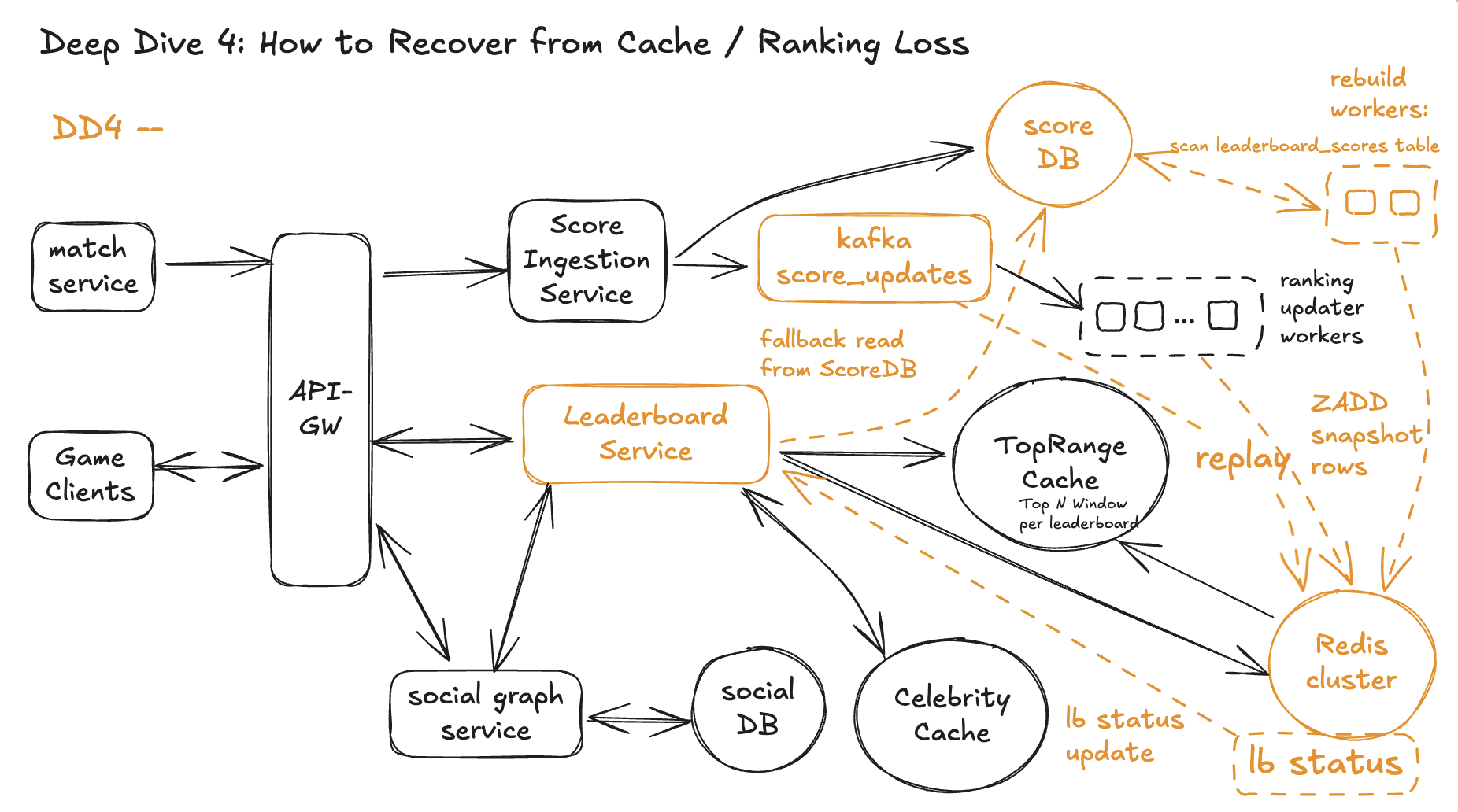
DD4 - How to Recover from Cache / Ranking Loss
Options to Discuss
- Rebuild only from DB (leaderboard_scores)
- Bulk scan each leaderboard and
ZADDinto Redis with the right ordering. - Simple, correct, but can be slow if we have many leaderboards / players.
- Bulk scan each leaderboard and
- Rebuild only from Kafka (score_updates)
- Start from earliest offsets and re-apply all updates.
- Perfect ordering, but replaying months of events can be too slow.
- Hybrid: DB snapshot + Kafka catch-up
- Use DB to quickly get a current snapshot.
- Then replay only the recent tail from Kafka to catch up.
- Apply idempotent logic using
version/match_id.
We’ll use Option 3.
If the Redis ranking cluster (and caches) are lost, we:
- Rebuild ZSETs from the canonical DB.
- For each
leaderboard_idon the failed node:- Scan
leaderboard_scoresin DB andZADD(player_id, score)back into a fresh ZSET in the correct order.
- Scan
- This gives us a current snapshot of the leaderboard in Redis again.
- For each
- Replay recent updates from Kafka to catch up.
- Ranking updaters consume the
score_updatestopic from “snapshot time” onward. - For each event
{leaderboard_id, player_id, new_score, version}, they update Redis only ifversionis newer than what’s stored. - When lag is near zero, the leaderboard is fully consistent again.
- Ranking updaters consume the
- Serve reads from DB while Redis is rebuilding.
- While a leaderboard is rebuilding:
- FR4 Top-N: query
leaderboard_scoresdirectly with anORDER BY … LIMIT N. - FR2/FR3: compute rank (and neighbors if we want) from DB + Social Graph, and optionally show a “syncing leaderboard” hint.
- FR4 Top-N: query
- Once Redis is caught up, we switch reads back to the normal Redis + TopRange / Celebrity caches path.
- While a leaderboard is rebuilding:
That’s it: DB = source of truth, Kafka = ordered log, Redis = rebuildable cache.
Workflow
Assume one Redis node (or the whole ranking cluster) loses its data.
Step 0 – Normal operation (baseline)
- Score Ingestion → DB (
leaderboard_scores) + Kafkascore_updates. - Ranking updaters consume Kafka → Redis ZSETs per
leaderboard_id. - Leaderboard Service reads from Redis + TopRange Cache + Celebrity Cache.
Step 1 – Detect failure & mark affected leaderboards
- Redis node fails / restarts empty.
- Health checks / monitoring detect:
- either node down or ZSETs missing for the leaderboards that node owns.
- A small coordinator (or config) marks those
leaderboard_ids as:status = DEGRADED_REBUILDINGin an internal map.
Effect: Leaderboard Service knows “Redis data for these leaderboards is not trustworthy right now.”
Step 2 – Switch reads to DB fallback for those leaderboards
While a leaderboard_id is DEGRADED_REBUILDING:
- FR4 Top-N
- Leaderboard Service runs a DB query:
- FR2 (my global rank + K neighbors)Simple, correct fallback:
- Read my row from
leaderboard_scores. - Compute my rank as:
- Read my row from
- Optionally fetch a small window of neighbors around me from DB using
ORDER BY ... LIMIT ... OFFSET ...(we accept higher latency here). - Add a “leaderboard is syncing” flag in the response.
- FR3 (friends rank)
- Same as before but using DB instead of Redis:
- Social Graph →
friend_ids. - Query
leaderboard_scoresfor those friends. - Sort in memory and compute
friends_rank + neighbors.
- Social Graph →
- Same as before but using DB instead of Redis:
Reads stay correct, just slower. UX can show a tiny “syncing” hint.
Step 3 – Rebuild Redis ZSETs from DB snapshot
In parallel, a Rebuild Worker for that Redis node:
- Enumerates all
leaderboard_ids that belong to the failed node. - For each
lb:
- Scans
leaderboard_scores:
- For each row, ZADD into Redis:
- This reconstructs the full sorted set for that leaderboard.
After this step, Redis has a correct snapshot as of “snapshot time” (when DB was read).
Step 4 – Catch up from Kafka tail
To close the small gap between “snapshot time” and “now”:
- Ranking updaters start consuming
score_updatesfor those leaderboards from snapshot time onward. - Each event contains
{leaderboard_id, player_id, new_score, version}(from DD4). - For each event:
- Read current
versionfor that player in Redis. - If
event.version > redis.version→ apply update (ZADD/ score change). - Else → ignore (stale / duplicate).
- Read current
When lag to the head of Kafka is near zero:
- Mark each rebuilt
leaderboard_idasHEALTHYin the coordinator.
Step 5 – Flip reads back to Redis + warm caches
Once a leaderboard is HEALTHY again:
- Leaderboard Service resumes normal DD2/DD3 read path for that
leaderboard_id:- Celebrity Cache → TopRange Cache → Redis ZSET.
- TopRange Cache is re-warmed automatically:
- As soon as top ranks get updated, the ranking node refreshes the top window again.
- Celebrity Cache repopulates on demand from live reads.
Design Diagram